


Machine Learns #42
China's new AI Agent Manus, Microsoft and OpenAI slowly separating, Anthropic raised $3.5 billion, Meta tests new AI chips, Google released Gemma-3 models, LLMVoX adds voice to LLMs.

📌 Bookmarks
Manus, a new AI agent from China. Early testers praise its performance, suggesting it may signify a shift in AI power dynamics, challenging U.S. dominance in the field. Access is currently limited.
Microsoft is developing in-house AI reasoning models to compete with OpenAI and may offer them to developers.
Anthropic launches a revamped platform enabling cross-functional collaboration on AI, enhancing accessibility for non-technical teams.
Anthropic raises $3.5 billion to enhance its AI systems and expand its global presence, bringing total funding to $18.2 billion.
Google holds a 14% stake in Anthropic, capped at 15%, with no voting rights. It plans to invest an additional $750 million through convertible debt, totaling over $3 billion. This investment is under scrutiny amid an antitrust case.
OpenAI pushes AI agent capabilities with new developer API
OpenAI plans to charge up to $20,000 a month for specialized AI agents tailored for various applications, including PhD-level research support.
CoreWeave has signed an $11.9 billion contract with OpenAI ahead of its IPO, marking a significant partnership in the tech industry.
Meta is reportedly testing in-house chips for AI training
The rise of large data centers for AI and poses significant energy consumption challenges, potentially doubling electricity demand and straining local infrastructure, while transparency about AI's energy needs remains limited.
After quitting a FAANG job due to concerns about automation, it reflects on the rapid changes in engineering roles driven by AI, predicting that many knowledge work jobs will soon be performed by AI agents, leaving humans to manage and oversee these systems instead of engaging in intellectually challenging tasks.
Stanford researchers have discovered a natural peptide, BRP, that mimics the appetite-suppressing effects of Ozempic without its side effects, showing promising results in animal tests and paving the way for potential human clinical trials.
Larry Page is launching a new AI startup, Dynatomics, focused on optimizing product manufacturing designs.
Exploring the moral implications of AI consciousness and the future of AI welfare through expert insights.
Australian man survives 100 days with artificial heart in world-first success
🤖 Model Releases
HunyuanVideo-I2V is a customizable image-to-video model that leverages advanced video generation techniques to create high-quality videos from static images.
Audio Flamingo 2 is an audio-language model with long-audio understanding and expert reasoning abilities. It comes with 3 models with 0.5B, 1.5B, and 3B parameters.
Smart-Turn is an audio turn detection model aiming to improve conversational AI by matching human-like response timing.
Babel is a suit of multilingual large language models serving over 90% of global speakers.
QwQ-32B is a 32 billion parameter language model that enhances reasoning capabilities through scalable Reinforcement Learning, achieving performance comparable to larger models like DeepSeek-R1.
DiffRhythm is a diffusion-based song generation model that is capable of creating full-length songs.
Edits - (released just after I published this issue)
Gemma-3 is a new family of LLMs from Google with 1B, 4B, 12B, and 27B model sizes. It also extends the 8k context length of Gemma2 to 32k (1B) and 128k. Models >1B also supports multimodality with images and +140 languages.
Reka Flash 3 is a 21B general-purpose reasoning model designed for low latency and on-device deployment, performing competitively with proprietary models.
📎 Papers
LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
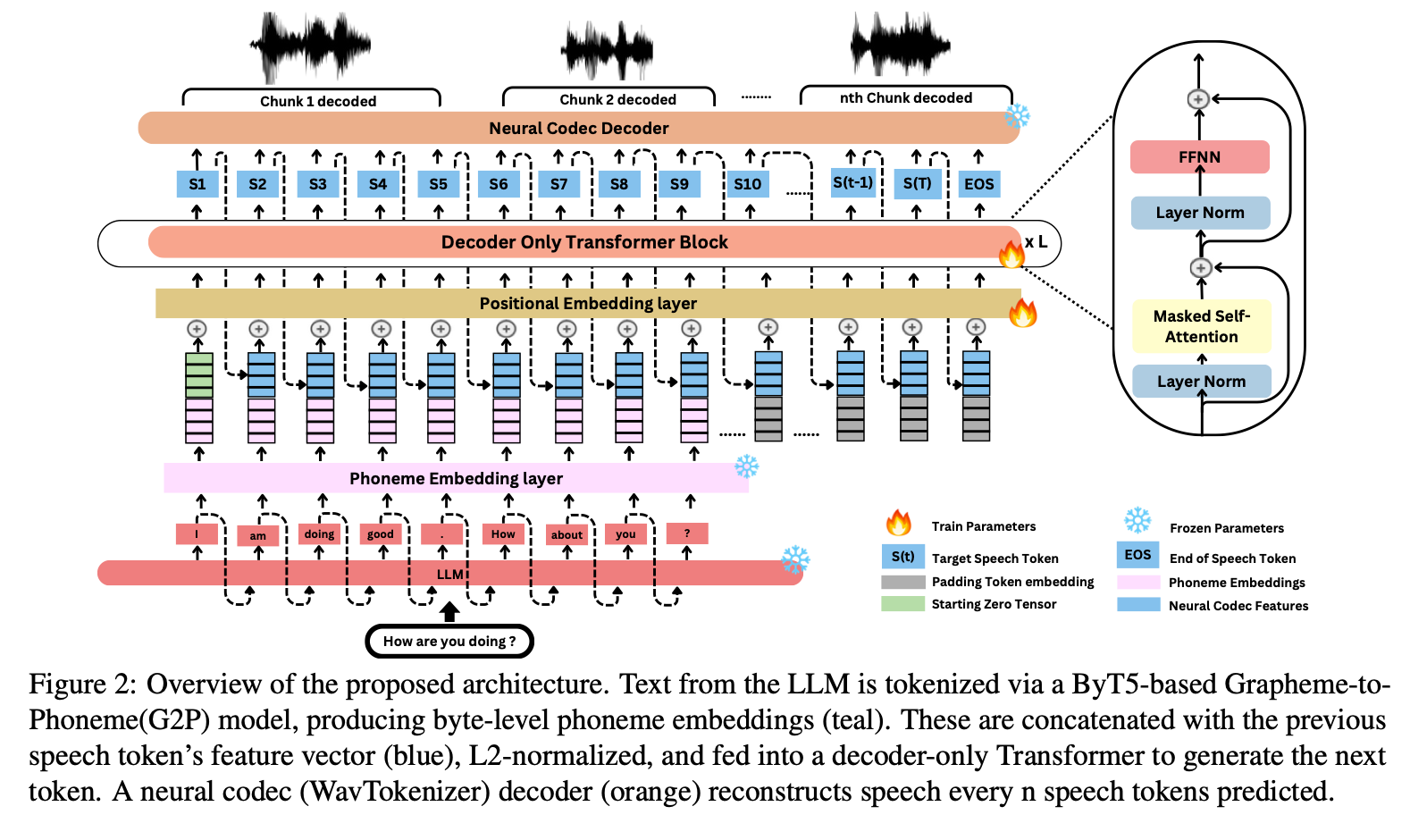
What's new
An autoregressive streaming TTS model aiming to add speech frontends to any large language model (LLM).
LLM-agnostic design that preserves base LLM capabilities.
Lightweight 30M-parameter framework.
How it works
Trained with frozen LLM weights to maintain LLM performance.
Passing LLM output text to the TTS model with pre-trained Byte-Level Grapheme-to-Phoneme Embedding.
Embeddings are concatinated with the previous speech token’s feature vector as input to the TTS model.
This input format allows the model to generate speech tokens without pre-fill time.
Uses a GPT-2 like decoder only base model for TTS.
Adapts to new languages easily with minimal data.
Utilizes a multi-queue token streaming system for continuous speech generation.
Results
Achieves a WER of 3.70% and UTMOS score of 4.05.
End-to-end latency of 475ms.
Outperforms existing speech-enabled LLMs in speech quality and latency.
♥️ I loved this paper !!
UniWav: Towards Unified Pre-training for Speech Representation Learning and Generation

What's new
First unified pre-training method for speech representation learning and generation.
How it works
Uses an encoder-decoder framework called UniWav.
Jointly learns a representation encoder and generative audio decoder.
Designed for both discriminative and generative tasks in speech.
Results
Achieves comparable performance to existing foundation models on speech recognition, text-to-speech, and speech tokenization.
Forgetting Transformer: Softmax Attention with a Forget Gate
What's new
Forgetting attention mechanism in Transformers. (FoX)
How it works
Incorporates a forget gate by down-weighting unnormalized attention scores.
Compatible with FlashAttention and does not require positional embeddings.
Results
FoX outperforms Transformer on long-context language modeling and length extrapolation.
Performs on par with Transformer on long-context downstream tasks.
Retains superior long-context capabilities over recurrent models like Mamba-2, HGRN2, and DeltaNet.
👩💻 Open Source
GitHub - yuanchenyang/smalldiffusion: Simple and readable code for training and sampling from diffusion models
GitHub - mannaandpoem/OpenManus: Open-source implementation of the new AI agent Manus.
GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.