


Machine Learns #46
Mira Murati poaching researchers at ICLR, OpenAI launches gpt-image-1 API, DeepMind UK staff unionizing, Qwen3 & F Lite model releases, ICLR conference dominated by China, ICLR paper highlights

👋 Everyone

I was at ICLR in Singapore last week, where I had the chance to meet many of you. I also had the chance to attend some great talks and poster sessions. We as Cantina Labs also had a great cocktail party, where I met some of you.
Some of highlights from the conference:
Conference was dominated by Chinese organizations. Both company booths and papers.
Great talk by Deep Mind on Open Ended AI research. I hope the talk will be available online soon.
A lot of papers about AI safety and alignment.
Accessibility of AI research is in big trouble. Except for the company labs, research labs were all limited by resources and they focused on more theoretical aspects of AI or safety and alignment.
Company labs were more focused on incremental ideas but large scale applications.
LLMs, AI safety, Diffusion models, Generation AI were the main topics of the conference.
And some gossip. I saw Mira Murati interviewing people from Byte Dance and Anthropic for her new startup with $20B funding. The Thinking Machines Lab has 11 people currently with no business idea for now. We'll see if all this is a fluff or not.
📌 Bookmarks
A recent study reveals that a significant portion of Generation Z believes artificial intelligence is already conscious, highlighting their complex relationship with technology.
Character.AI launches AvatarFX, a video generation model that animates characters and raises concerns over potential misuse and emotional manipulation.
OpenAI launches gpt-image-1 API for high-quality image generation, enabling developers to integrate versatile image creation into their tools.
Mistral announced new API for creating classifiers based on Mistral foundation models, allowing users to build custom classifiers for various tasks.
Elon Musk's xAI Holdings is reportedly raising $20 billion in funding, potentially valuing the company at over $120 billion, making it the second-largest private funding round ever.
DeepMind UK staff plan to unionize to challenge the company's AI deals with defense groups linked to Israel.
Impact of superhuman AI by 2027, predicting significant advancements and potential risks in AI development and governance.
Google's AI chatbot Gemini reaches 350 million monthly users, showing significant growth despite trailing behind competitors like ChatGPT.
China launches the world's first commercial 10G broadband network, delivering ultra-fast internet speeds and enhancing high-bandwidth applications.
Rebellions, South Korea's first AI chip unicorn, aims to challenge global giants like Nvidia with its energy-efficient chips following a merger with Sapeon Korea.
Apple is now assembling the iPhone 16e in Brazil to mitigate US tariffs amid ongoing trade tensions.
OpenAI is developing a social network prototype that may integrate with ChatGPT, intensifying competition with Elon Musk and Meta.
China launches an $8.2 billion AI fund to boost its domestic ecosystem and reduce dependence on U.S. chip manufacturers like Nvidia and Broadcom.
🤖 Model releases
Qwen3 is an advanced large language model series developed by Alibaba's Qwen team, featuring enhanced reasoning capabilities, support for 100+ languages, seamless switching between thinking and non-thinking modes.
F Lite is a 10B parameter diffusion image generation model created by Freepik and Fal, trained exclusively on copyright-safe and SFW content.
Kimi-Audio is an open-source audio foundation model designed for audio understanding, generation, and conversation, achieving state-of-the-art performance across diverse audio processing tasks.
DIA-Multilingual is a TTS model that generates realistic dialogue in over 30 languages using phonemization and style transfer techniques.
NatureLM-audio is the first audio-language foundation model designed for bioacoustics, enabling tasks like species classification and detection using a diverse dataset of text-audio pairs.
Embed 4 enables enterprises to securely retrieve multimodal data with state-of-the-art accuracy and efficiency for building AI applications.
The Describe Anything Model (DAM) generates detailed descriptions for specified regions in images or videos using points, boxes, or masks.
Meta FAIR releases new models enhancing perception, localization, and reasoning for advanced machine intelligence, including the Perception Encoder and Collaborative Reasoner.
📎 Papers - (ICLR selections)
An Evolved Universal Transformer Memory
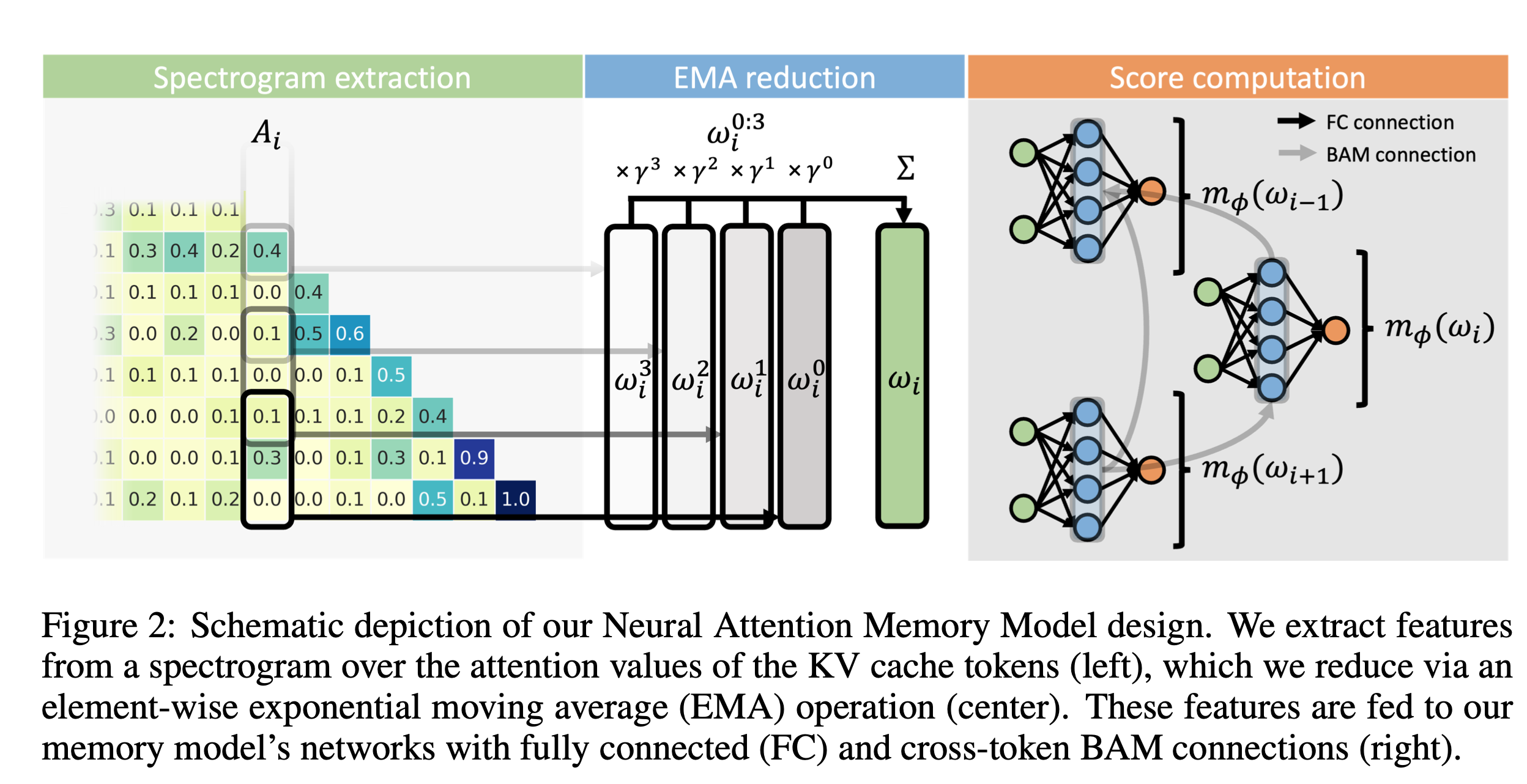
What's new
New memory system for transformers
Performance improvements in language tasks
Zero-shot transfer to different architectures and input modalities
How it works
Introduces Neural Attention Memory Models (NAMMs)
Learned network for memory management
Evolves NAMMs atop pre-trained transformers
Focuses on relevant information for individual layers and attention heads
Results
Substantial performance improvements across long-context benchmarks
Reduces model's input contexts significantly
Generality allows zero-shot transfer to new transformer architectures
Melodi: Exploring Memory Compression for Long Contexts

What's new
A novel memory architecture for processing long documents with short context windows.
Hierarchical compression scheme for representing short-term and long-term memory.
How it works
Short-term memory uses recurrent compression across multiple layers to ensure smooth transitions between context windows.
Long-term memory aggregates information from all previous windows in a single layer, reducing forgetting.
Results
Melodi outperforms the Memorizing Transformer on various long-context datasets while reducing memory usage by a factor of 8.
Achieves perplexity scores of 10.44 on PG-19 and 2.11 on arXiv Math.
ImageFolder: Autoregressive Image Generation with Folded Tokens

What's new
A semantic image tokenizer for autoregressive image generation.
Balances token length and reconstruction quality through folding spatially aligned tokens.
Utilizes product quantization, semantic regularization, and quantizer dropout for improved representation.
How it works
Tokenizes images into semantic and detail tokens using product quantization.
Employs a dual-branch architecture to capture different image aspects.
Implements parallel decoding to predict multiple tokens from a single logit, reducing token length.
Results
Achieves superior generation quality with a shorter token length (265 tokens).
Outperforms existing models like LlamaGen and VAR in image generation tasks.
Demonstrates significant improvements in Fréchet Inception Distance (FID) and Inception Score (IS).
One Step Diffusion via Shortcut Models

What's new
Distilling diffusion models with shortcut models for generative modeling.
Enables high-quality image generation in fewer steps without complex training regimes.
How it works
Shortcut models condition on both noise level and desired step size.
Trained end-to-end in a single run, avoiding separate distillation phases.
Achieves one-step denoising by learning to jump ahead in the generation process.
Results
Shortcut models outperform previous methods in few-step and one-step generation.
Maintains performance of baseline models on many-step generation.
Demonstrated effectiveness on CelebA-HQ and Imagenet-256 benchmarks.
Other papers
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Diffusion Models are Evolutionary Algorithms
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
👨💻 Open-source
GitHub - kortix-ai/suna: Suna is an open-source AI agent designed to assist with real-world tasks through natural conversation, offering powerful tools for research, data analysis, and workflow automation.
ZFTurbo/Music-Source-Separation-Training: Repository for training models for music source separation.
GitHub - fjiang9/NKF-AEC: Acoustic Echo Cancellation with Nerual Kalman Filtering
wavlab-speech/versa: Versatile Evaluation of Speech and Audio
GitHub - cocoindex-io/cocoindex: ETL framework to turn your data AI-ready - with realtime incremental updates and support custom logic like lego.