


Machine Learns #48
OpenAI's 'Sign in with ChatGPT', Meta's AGI ambitions, new models like Gemma 3 & MAGI-1, research breakthroughs in KV caching for diffusion & PaTH Attention, and fresh open-source releases.

📌 Bookmarks
China organized the first humanoid kickboxing tournament
OpenAI may soon let you 'sign in with ChatGPT' for other apps
Meta shuffles AI, AGI teams to compete with the other bigs.
Regenerative cell therapy trial has been approved to potentially repair spinal cord injuries, offering new hope for millions affected by this condition.
Valve CEO Gabe Newell’s Neuralink competitor is expecting its first brain chip this year
Billionaire Baiju Bhatt's startup Aetherflux aims to harness solar power from space and beam it to Earth using lasers, with a demonstration planned for 2026.
Aurora launches commercial self-driving truck service in Texas
Google quantum exec says tech is '5 years out from a real breakout'
Anthropic launches a voice mode for Claude
🤖 Model Releases
MAGI-1 is a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames.
QwenLong-L1-32B is the first long-context language representation model trained with reinforcement learning, achieving state-of-the-art performance on long-context reasoning benchmarks.
Toto is a state-of-the-art time-series foundation model designed for multi-variate forecasting, optimized for observability metrics and capable of zero-shot forecasting.
Collection of Gemma 3 variants designed for enhanced performance in medical text and image comprehension, aimed at accelerating healthcare AI applications.
Gemma 3n is a mobile-first model with multimodal understanding, optimized for on-device performance.
BAGEL is an open-source multimodal foundation model with 7B active parameters, excelling in multimodal understanding, text-to-image generation, and advanced image editing tasks.
OuteTTS-1.0-0.6B is a speech synthesis and voice cloning model thay comes with batched inference capabilities.
Wan2.1 is an advanced suite of video generative models that excels in various tasks, including Text-to-Video and Image-to-Video, while supporting consumer-grade GPUs.
Stable Audio Open Small generates variable-length stereo audio from text prompts using a latent diffusion model based on a transformer architecture.
📎 Papers
PaTH Attention: Position Encoding via Accumulating Householder Transformations
What's new
PaTH (Position Encoding via Accumulating Householder Transformations) attention mechanism.
Improved perf. on state-tracking tasks and long-context understanding.
Combines data-dependent position encoding with efficient training algorithms.
How it works
PaTH uses a dynamic, data-dependent transition matrix for computing bilinear attention logits.
Unlike traditional methods (like RoPE), which use fixed transformations, PaTH adapts its state transitions based on input data.
Utilizes Householder-like transformations to create a cumulative product of matrices, capturing the transformation between positions dynamically.
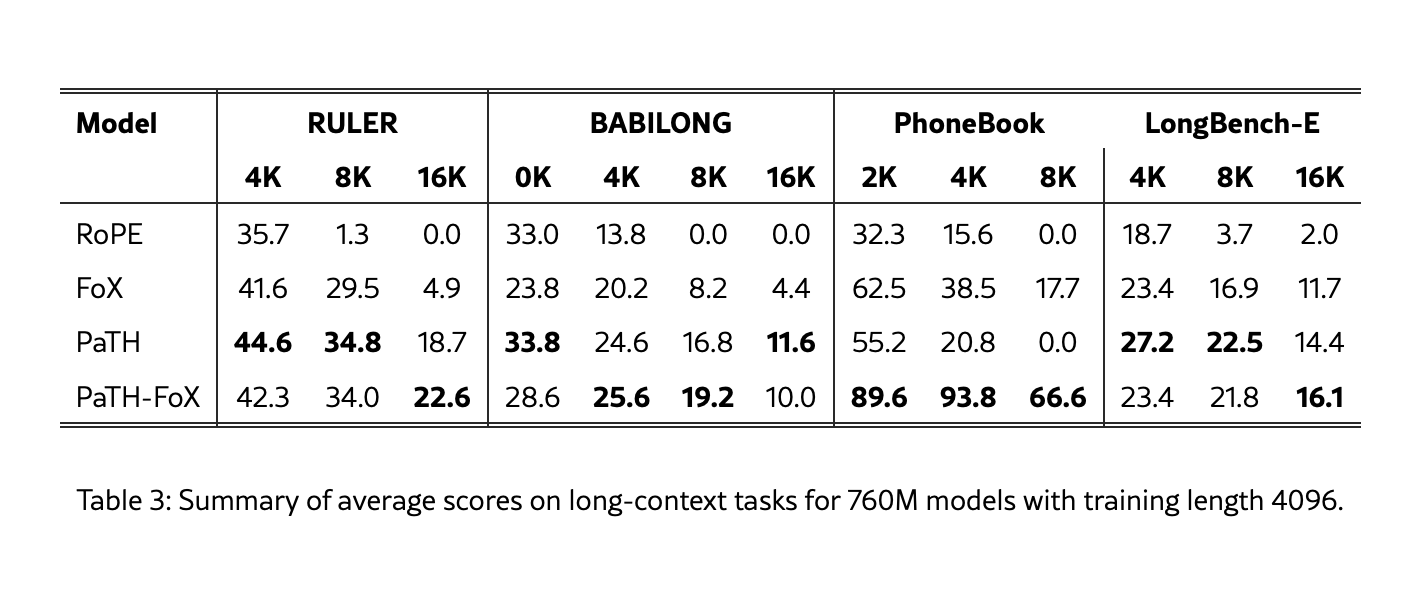
Results
PaTH outperforms RoPE and FoX (Forgetting Transformer) across various benchmarks, particularly in state-tracking tasks and length extrapolation.
Combined with FoX performed the best.
dKV-Cache: The Cache for Diffusion Language Models
What's new
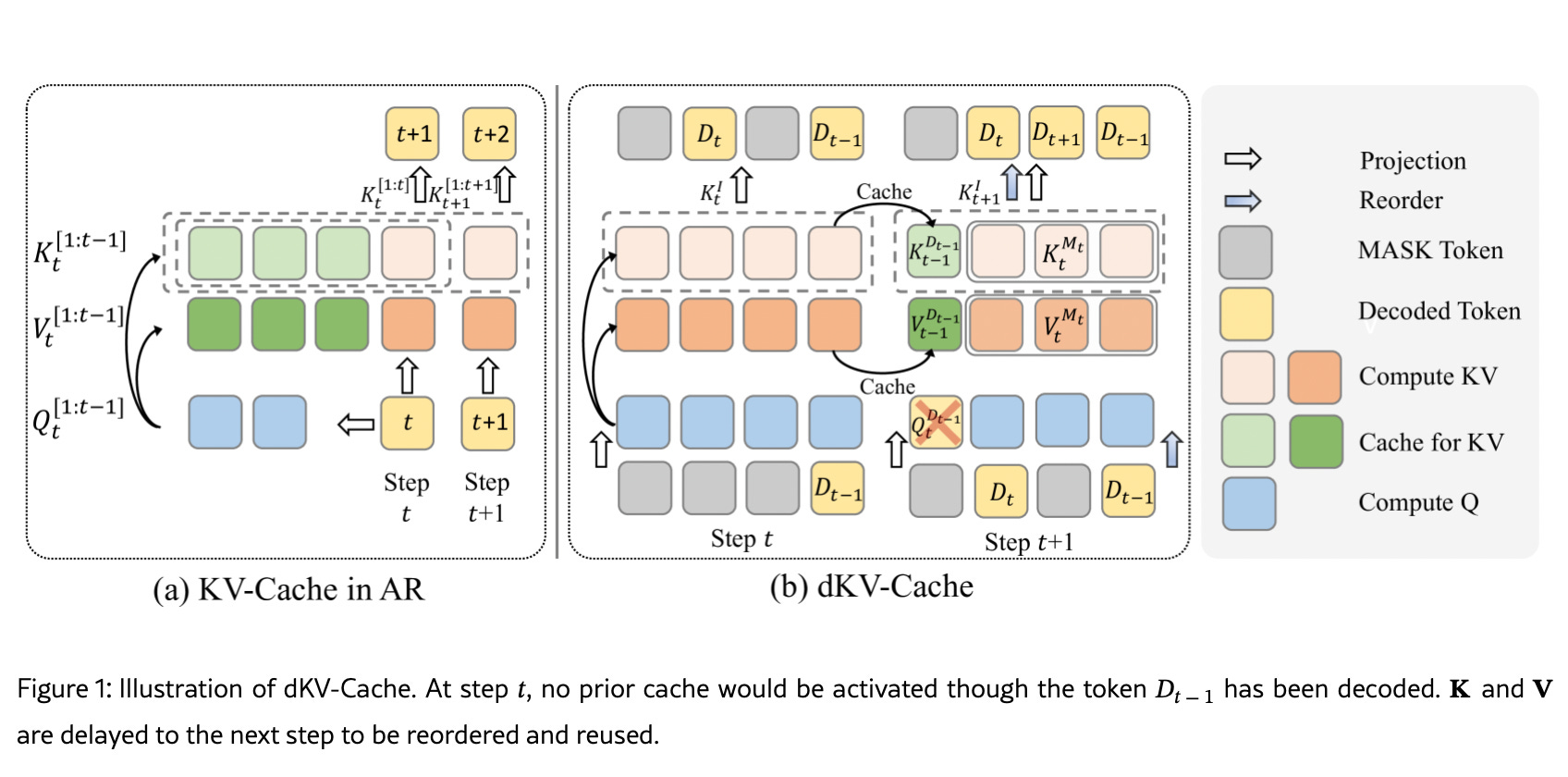
Delayed KV-Cache mechanism for Diffusion Language Models (DLMs) to enhance inference speed.
How it works
Benefiting the fact that K/V vectors a highly similar between time steps.
Cache K/V states 1 step after their tokens are decoder.
1 step delay improves the stability and reduce the performance loss.
Two variants are introduced:
dKV-Cache-Decode:
Provides almost lossless acceleration.
Improved perf. on long sequences
dKV-Cache-Greedy:
Features aggressive caching with a reduced lifespan.
Higher speed-ups though with some performance degradation.
Overall, the dKV-Cache achieves a 2-10× speedup in inference.
Results
Evaluated on various benchmarks, showing acceleration in general language understanding, mathematical, and code-generation tasks.
MMaDA: Multimodal Large Diffusion Language Models
What's new
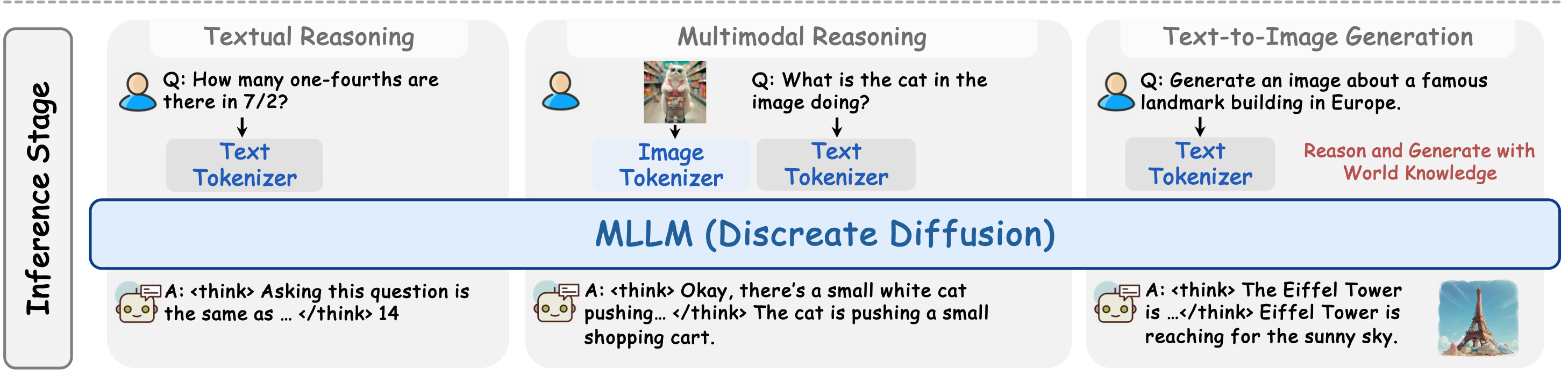
MMaDA, a novel class of multimodal diffusion foundation models.
Unified diffusion architecture with a shared probabilistic formulation.
Mixed long chain-of-thought (CoT) fine-tuning strategy.
UniGRPO, a unified policy-gradient-based RL algorithm for diffusion models.
How it works
Unified diffusion architecture eliminates modality-specific components, allowing seamless integration of different data types.
Mixed CoT fine-tuning aligns reasoning processes between textual and visual domains.
UniGRPO employs diversified reward modeling to unify post-training across reasoning and generation tasks.
Results
MMaDA-8B demonstrates strong generalization capabilities as a unified multimodal foundation model.
Outperforms LLaMA-3-7B and Qwen2-7B in textual reasoning.
Outperforms Show-o and SEED-X in multimodal understanding.
Outperforms SDXL and Janus in text-to-image generation.
👨💻 Open-Source
Hyperparam introduces a suite of open-source tools designed to enhance data quality and exploration in machine learning workflows directly in the browser.
GitHub - suitenumerique/docs: A collaborative note taking, wiki and documentation platform that scales. Built with Django and React. Opensource alternative to Notion or Outline.
google-research/big_vision open-source release of the Google's JetFormer. It is a autoregressive model that generates high-fidelity images and text without relying on a separate encoder-decoder model.