


Machine Learns #51
OpenAI locks down labs after DeepSeek allegations, CEO exits X & Anthropic reaches $4B, 11 new models include Kyutai TTS & FLUX.1 Kontext, plus research in ultra-fast dLLMs & TalkingMachines

Join us on Discord at for more discussions and updates!
📌 Bookmarks
Linda Yaccarino steps down as CEO of Elon Musk's X after two years, expressing gratitude for the opportunity to transform the platform.
OpenAI has enhanced its security measures, including biometric scans and restricted access, to prevent espionage after allegations that Chinese rival DeepSeek copied its models. The company has adopted a "deny-by-default" policy and hired former Palantir security chief Dane Stuckey to oversee these changes amid rising geopolitical tensions over AI technology.
Exploring the evolving role of AI tools in software engineering, their impact on productivity, and the contrasting perspectives of executives and developers.
Anthropic's annual revenue reportedly reaches $4 billion, highlighting its role in the competitive AI landscape and recent leadership changes at Anysphere.
Apple is exploring Project ACDC to create its own cloud services, potentially competing with AWS, Azure, and Google Cloud using its own silicon.
AI-powered virtual YouTubers, or VTubers, are revolutionizing content creation and earning millions, fueled by advancements in artificial intelligence.
Preliminary evaluation of DeepSeek and Qwen models reveals mid-2025 capabilities comparable to late 2024 frontier models, with insights on performance and cheating attempts.
The shift from prompt engineering to context engineering in AI, emphasizing the importance of providing rich context for effective agent performance.
🤖 Model Releases
FlexOlmo-7x7B-1T is a Mixture-of-Experts language model designed for flexible data collaboration, allowing data owners to contribute without relinquishing control over their data.
One-Step Diffusion model enhances video super-resolution by ensuring detail richness and temporal consistency through a dual-stage training scheme.
SmolLM3 is a small, multilingual, long-context reasoning model with competitive performance, supporting up to 128k context and dual instruction modes for enhanced reasoning capabilities.
Tar is a unified MLLM with text-aligned representations, offering various models for any-to-any tasks and integrating visual understanding and generation.
Jamba Large 1.7 is an advanced AI model that enhances grounding and instruction-following capabilities, optimized for various business applications with a 256K context window.
Kyutai TTS is a state-of-the-art text-to-speech model optimized for real-time usage, featuring ultra-low latency and voice cloning capabilities.
Qwen VLo is a unified multimodal model that enhances image understanding and generation, allowing users to create and modify images through natural language instructions.
XVerse is an official model for consistent multi-subject control of identity and semantic attributes via DiT modulation.
FLUX.1 Kontext [dev] is an open-weight generative image editing model that delivers proprietary-level performance on consumer hardware, enabling advanced editing tasks with a focus on character preservation and iterative edits.
Hunyuan-A13B is an innovative open-source large language model designed for efficiency and scalability, featuring 80 billion parameters with 13 billion active parameters, optimized for advanced reasoning and general-purpose applications.
ERNIE 4.5 is a large-scale multimodal model family with 10 variants, enhancing multimodal understanding and performance across text and visual tasks, optimized for efficiency and publicly accessible under Apache 2.0.
📎 Papers
Mercury: Ultra-Fast Language Models Based on Diffusion
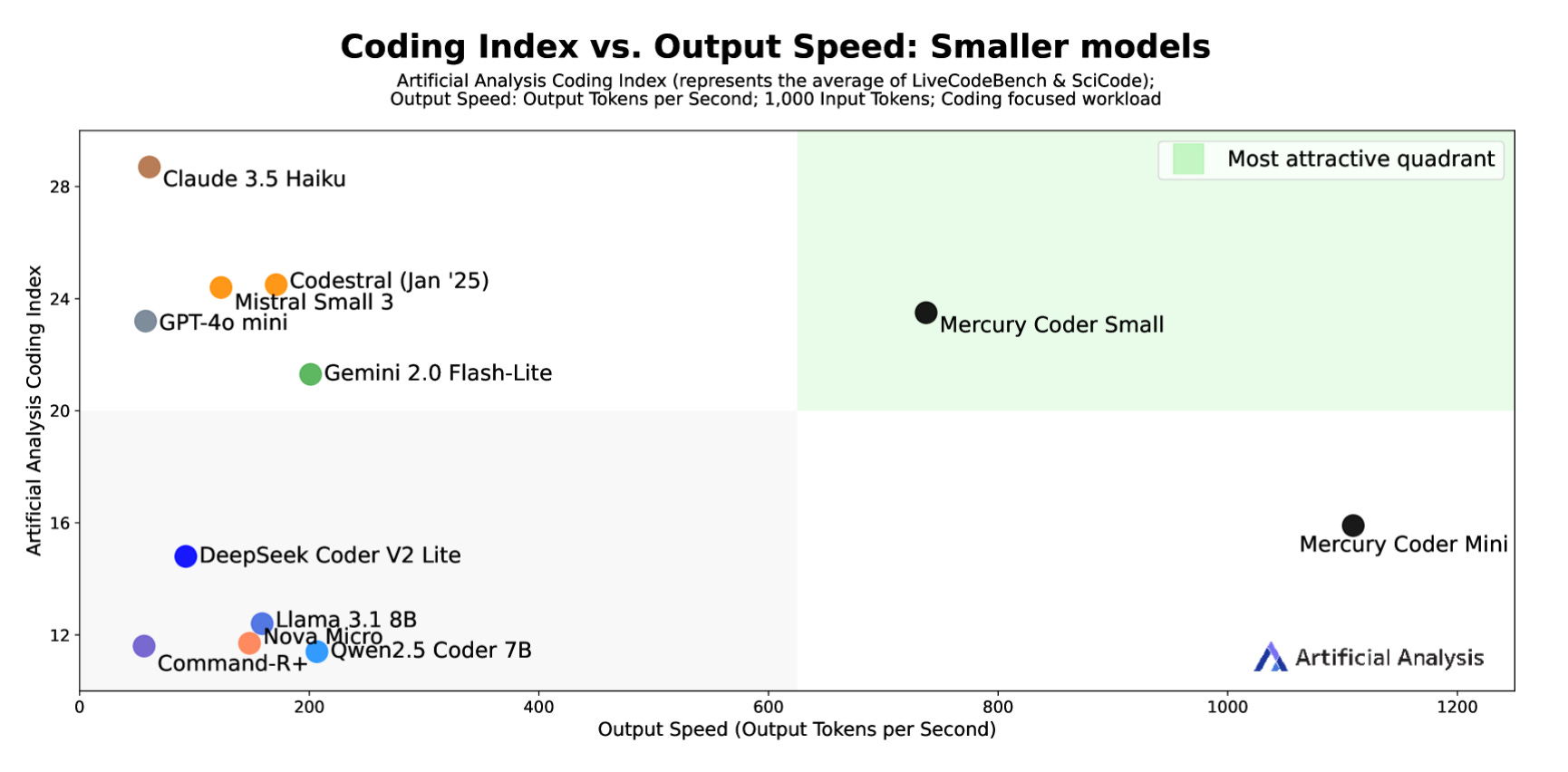
What's new
A new generation of large language models (LLMs) based on diffusion.
Mercury Coder, the first set of diffusion LLMs designed specifically for coding applications.
Achieves state-of-the-art throughputs: 1109 tokens/sec for Mini and 737 tokens/sec for Small on NVIDIA H100 GPUs.
How it works
Mercury models utilize the Transformer architecture and are trained to predict multiple tokens in parallel.
Diffusion models generate outputs by iteratively refining data starting from random noise, transforming it into coherent samples.
The training process involves a forward (noising) and reverse (denoising) process, where the model learns to denoise data based on a known prior noise distribution.
The models can generate answers in a coarse-to-fine manner, modifying multiple tokens simultaneously, enhancing efficiency and quality.
Supports context lengths up to 32,768 tokens, extendable to 128k tokens.
Inference methods allow for flexible generation conditioned on prompts, supporting zero-shot and few-shot prompting.
Results
Mercury Coder models outperform existing models in speed and maintain comparable quality.
Independent evaluations show Mercury Coder Mini and Small rank high in coding benchmarks, achieving strong performance across multiple programming languages.
On Copilot Arena, Mercury Coder Mini ranks second in quality and is the fastest model with an average latency of 25 ms.
TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models
What's new
A framework for real-time, audio-driven character animation.
Combines pretrained video generation models with audio large language models (LLMs).
Capable of generating infinite-length video streams without error accumulation.
How it works
Model Adaptation: Utilizes a pretrained image-to-video (I2V) model and adapts it for audio-driven generation using specialized attention mechanisms.
Infinite-Length Generation: Implements Distribution Matching Distillation (DMD) to allow autoregressive generation without error accumulation, enabling long video streams.
Real-Time Performance: Achieves low latency by distilling the model to 2 diffusion steps and optimizing system-level operations.
Audio Cross Attention: Modifies Cross Attention layers to process audio tokens, improving lip-sync accuracy by focusing on facial regions.
Speaking/Silence Mode: Detects if a character is speaking or silent, adjusting embeddings accordingly for accurate lip-syncing.
Asymmetric Distillation: Distills knowledge from a bidirectional teacher model to an autoregressive student model, optimizing for real-time generation.
System Optimizations: Includes Score-VAE disaggregation to separate diffusion and decoding processes across GPUs, enhancing throughput and reducing latency.
Results
Demonstrated real-time performance suitable for interactive video calls.
Successfully integrates audio LLMs for natural conversational interactions.
Achieves high-quality lip-synced animations from audio input.
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive Branching Tree Search
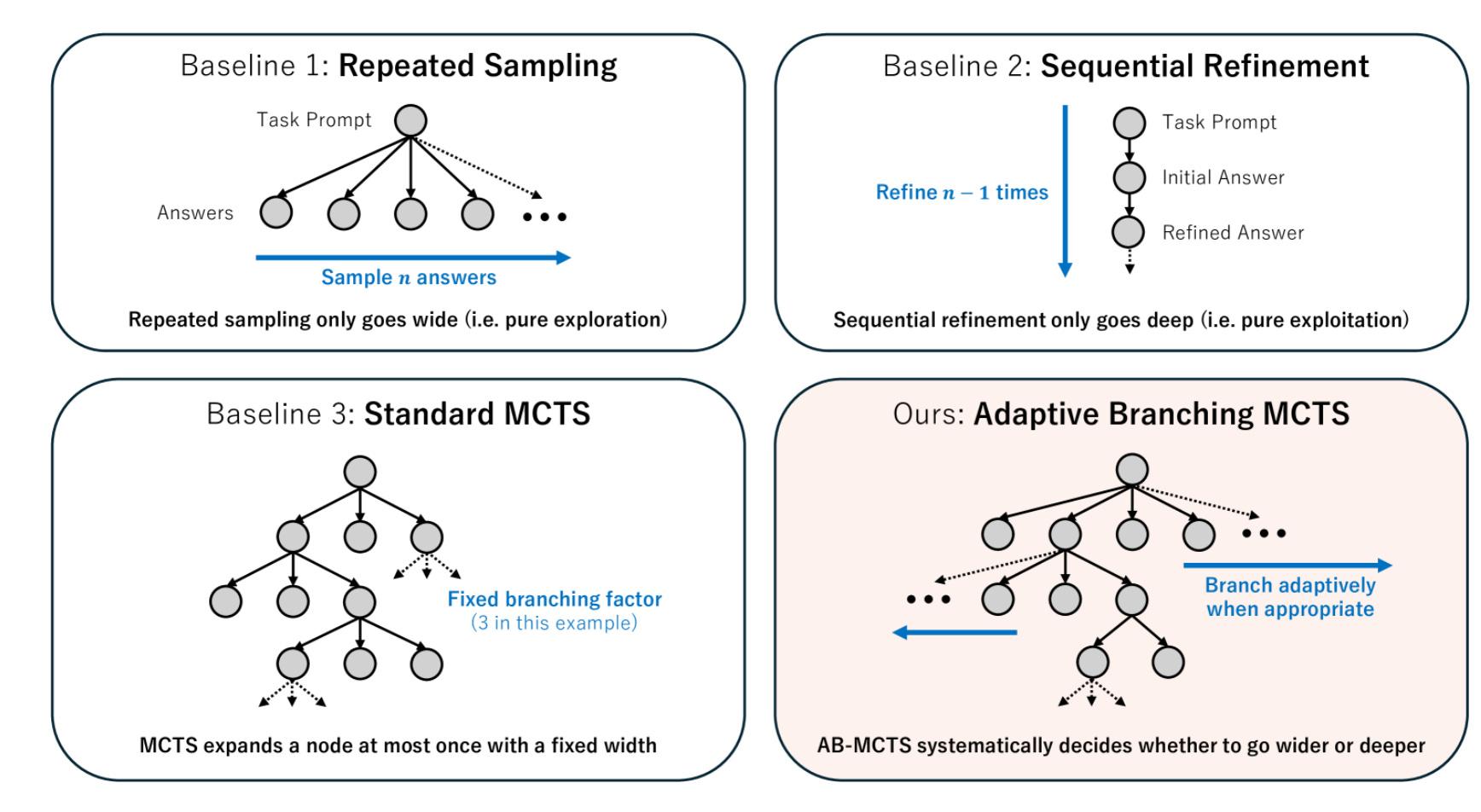
What's new
Adaptive Branching Monte Carlo Tree Search (AB-MCTS) framework.
Combines exploration and exploitation in LLM inference-time scaling.
Outperforms existing methods like repeated sampling and standard MCTS.
How it works
AB-MCTS generalizes repeated sampling by allowing multi-turn exploration and exploitation.
At each node in the search tree, it decides to "go wider" (expand new candidate responses) or "go deeper" (refine existing ones) based on external feedback.
Utilizes Bayesian decision-making to balance exploration and exploitation.
Introduces GEN nodes for generating new candidates and CONT nodes for refining existing answers.
Employs Thompson sampling for node selection, allowing for parallel expansion and efficient search.
Adapts branching dynamically, avoiding fixed-width constraints of traditional MCTS.
Results
AB-MCTS consistently outperforms baseline methods across diverse benchmarks (LiveCodeBench, CodeContest, ARC-AGI, MLE-Bench).
Achieves higher success rates and better average ranks compared to repeated sampling and standard MCTS.
Demonstrates scalability with increased generation budgets, maintaining performance improvements.
👨💻 Open-Source
Discover HelixDB, a native graph-vector database designed to seamlessly link legal cases and relevant precedents with contextual awareness.
GitHub - mirage-project/mirage: Mirage: Automatically Generating Fast GPU Kernels without Programming in Triton/CUDA
GitHub - tensorzero/tensorzero: TensorZero creates a feedback loop for optimizing LLM applications — turning production data into smarter, faster, and cheaper models.