
Machine Learns #52
KAT & Qwen3-235B models, Diffusion beats autoregressive in data-constrained settings, AdaMuon optimizer & multi-token prediction advances, plus SpeechSSM for long-form audio generation.

📣 Skipping Bookmarks this time - Miss it? Let me know.
💬 Come and chat with me on Discord.
🤖 Model Releases
KAT (Kwaipilot-AutoThink) is an open-source large-language model that optimizes reasoning by learning when to produce explicit chain-of-thought and when to answer directly, achieving strong factual and reasoning skills efficiently.
Qwen3-235B-A22B-Instruct-2507 is a causal language model with significant improvements in instruction following, logical reasoning, and long-context understanding, designed for enhanced user alignment and multilingual capabilities.
Pusa is a video diffusion model that utilizes vectorized timestep adaptation for fine-grained temporal control, achieving efficiency in image-to-video generation with reduced training costs and dataset sizes.
Canary-Qwen-2.5B is an English speech recognition model with 2.5 billion parameters, supporting automatic speech-to-text recognition and capable of functioning in both transcription and language model modes.
Audio Flamingo 3 is a Large Audio-Language Model designed for voice chat and multi-audio dialogue, capable of processing up to 10 minutes of audio inputs and built on a Transformer architecture using NVIDIA's hardware and software frameworks.
Kimi K2 is a mixture-of-experts language model with 32 billion activated parameters and 1 trillion total parameters, optimized for knowledge representation, reasoning, and coding tasks.
Phi-4-mini-flash-reasoning is a lightweight, transformer-based model optimized for high-quality mathematical reasoning tasks, supporting a 64K token context length and designed for efficiency in memory-constrained environments.
Devstral is an agentic LLM for software engineering tasks, excelling in code exploration and editing, with a long context window of 128k tokens and remarkable performance on SWE-bench.
LFM2 is a new generation of hybrid models by Liquid AI, designed for edge AI with enhanced quality, speed, and memory efficiency.
📎 Papers
visit here for more papers
Diffusion Beats Autoregressive in Data-Constrained Settings
What's new
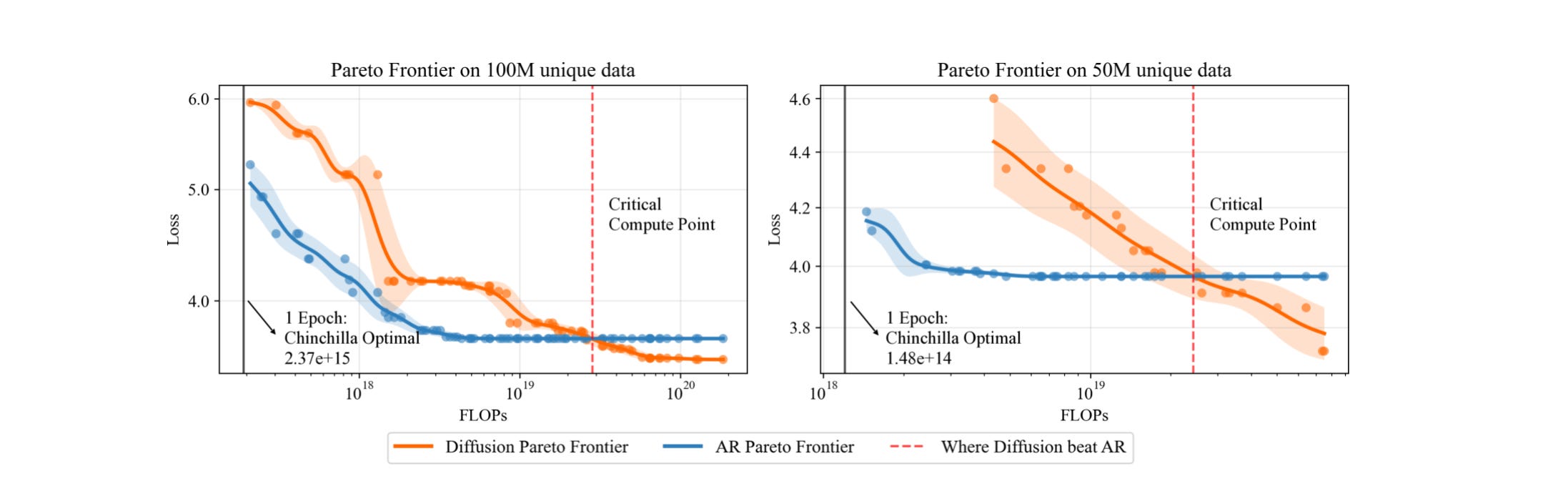
Diffusion models outperform autoregressive (AR) models in data-constrained settings.
New scaling laws for diffusion models established.
Diffusion models show better generalization and lower validation loss with repeated data.
How it works
Diffusion models use masked token prediction, allowing training on diverse token orderings.
Unlike AR models that predict tokens in a fixed left-to-right order, diffusion models factorize the joint distribution in a random order.
Training involves:
Corrupting input sequences by masking tokens.
Predicting original tokens at masked positions using bidirectional attention.
This approach exposes models to a variety of prediction tasks, enhancing data efficiency.
The study analyzes performance across different unique data sizes (25M, 50M, 100M tokens) and compute budgets.
A critical compute threshold is identified, beyond which diffusion models outperform AR models.
Results
Diffusion models achieve lower validation loss compared to AR models when trained on repeated data.
Performance improves significantly with more training epochs, showing no signs of overfitting.
Empirical validation loss indicates that diffusion models can leverage repeated data effectively, outperforming AR models in various tasks.
AdaMuon: Adaptive Muon Optimizer
What's new
AdaMuon, an adaptive learning-rate framework based on the Muon optimizer.
Enhancements include second-moment modulation and RMS-aligned rescaling.
How it works
AdaMuon builds on the Muon optimizer, which uses polar decomposition for structured updates in two-dimensional parameter spaces.
It incorporates:
A per-parameter second-moment modulation to capture gradient variance, improving update adaptivity.
An RMS-aligned rescaling mechanism to regulate update magnitude, aligning it with the parameter space structure.
The optimizer applies second-moment estimation after orthogonalization to maintain geometric benefits while adapting to local gradient variance.
This approach allows for fine-grained variance adaptation without compromising the structured updates provided by Muon.
Results
AdaMuon consistently outperforms both the original Muon and AdamW optimizers in terms of convergence speed and generalization performance across various model scales.
Demonstrated significant reductions in training tokens and wall-clock time needed to achieve final training and validation losses compared to AdamW.
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
What's new
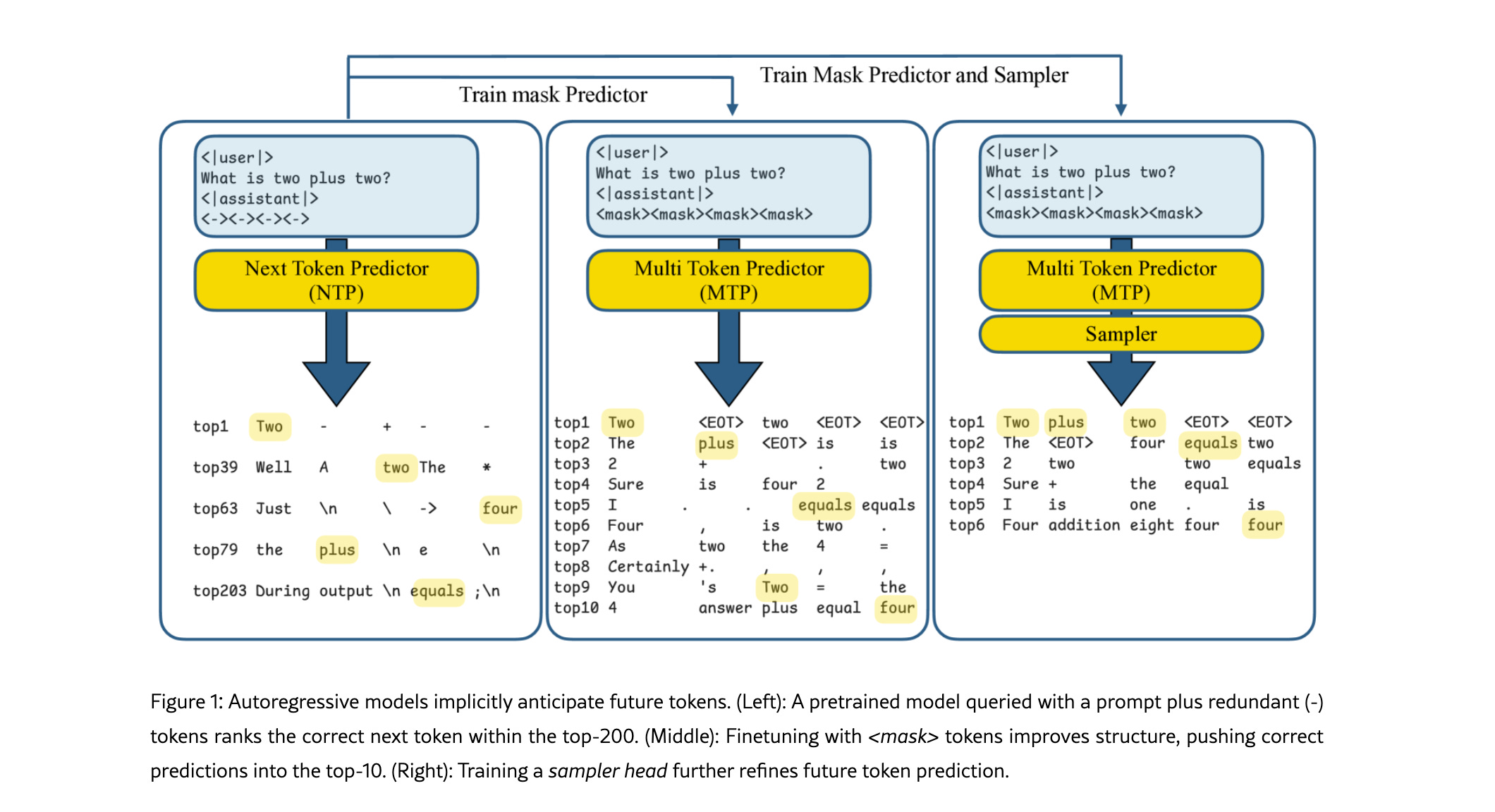
Novel framework for autoregressive language models enabling simultaneous prediction of multiple future tokens.
How it works
Masked-input formulation: predicts multiple future tokens from a common prefix.
Gated LoRA formulation: retains original LLM functionality while enabling multi-token prediction.
Lightweight, learnable sampler module: generates coherent sequences from predicted tokens.
Auxiliary training losses: includes consistency loss to enhance coherence and accuracy of generated tokens.
Speculative generation strategy: expands tokens quadratically into the future while maintaining high fidelity.
Results
Significant speedups achieved through supervised fine-tuning on pretrained models.
Code and math generation nearly 5x faster.
Improvement in general chat and knowledge tasks by almost 2.5x.
No loss in quality.
Long-Form Speech Generation with Spoken Language Models
What's new
SpeechSSM, a novel speech language model family designed for long-form speech generation without text intermediates.
Development of LibriSpeech-Long, a benchmark for evaluating long-form speech generation.
New evaluation metrics and methodologies for assessing speech generation quality.
How it works
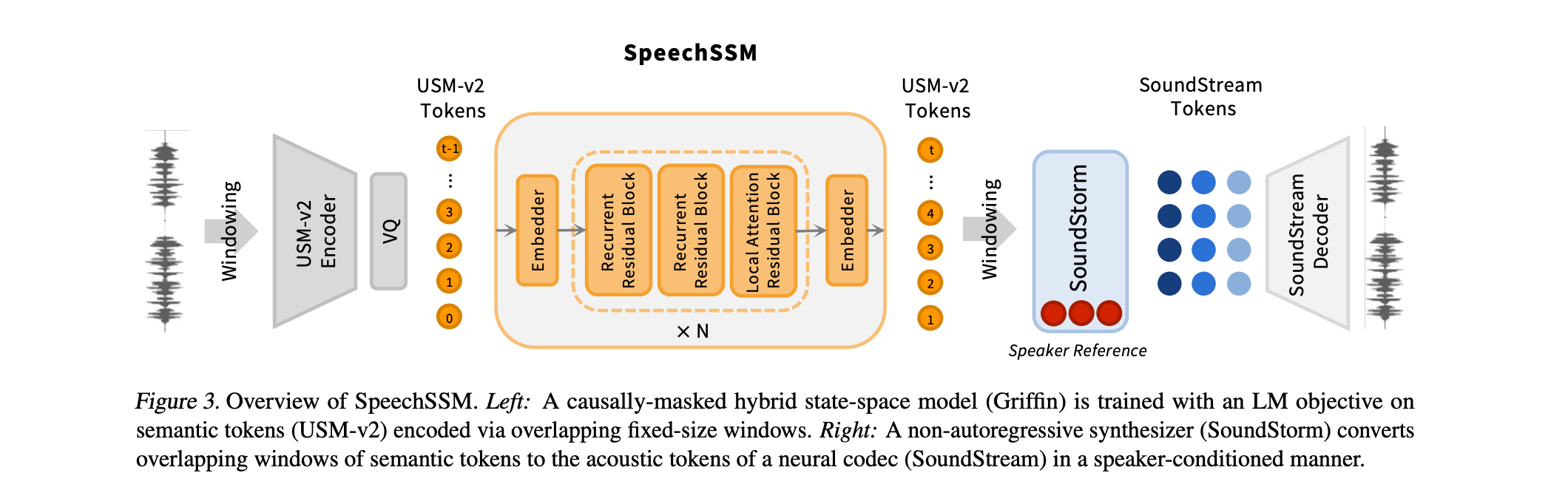
SpeechSSM leverages linear-time sequence modeling to maintain coherence and efficiency over long durations (up to 16 minutes).
Utilizes a hybrid architecture combining gated linear recurrent units (LRUs) and local multi-query attention (MQA) blocks for efficient context capture.
Employs a semantic tokenizer (USM-v2) trained on untranscribed audio, converting audio into fixed-rate pseudo-text for processing.
Generates low-level acoustic tokens conditioned on semantic tokens using a SoundStorm model, which reconstructs high-quality audio.
Implements windowed tokenization and decoding, processing audio in fixed segments with overlaps to minimize boundary artifacts.
Avoids implicit end-of-sequence tokens to enhance generative extrapolation beyond training durations.
Results
SpeechSSM outperforms existing spoken language models in coherence and efficiency for long-form speech generation.
Achieves better performance in naturalness and speaker similarity compared to baseline models.
Demonstrates significant improvements in evaluation metrics, including transcript perplexity and semantic coherence over time.
🧑💻 Open-Source
GitHub - mozilla-ai/any-agent: A single interface to use and evaluate different agent frameworks
GitHub - microsoft/ArchScale: Simple & Scalable Pretraining for Neural Architecture Research
HelixDB, a native graph-vector database designed to seamlessly link legal cases and relevant precedents with contextual awareness.