
Machine Learns #56
Diffusion LMs go mainstream, zero-shot model-size interpolation lands, “hippocampus” memory boosts long-context models, and tiny networks beat big ones at recursive reasoning

🤖 Model Releases
radicalnumerics/RND1-Base-0910 · Hugging Face — A 30B diffusion language model using a sparse MoE, converted from a pretrained autoregressive base.
Kwaipilot/KAT-Dev-72B-Exp · Hugging Face — Open 72B model for software engineering; 74.6% on SWE-Bench Verified with SWE-agent.
KaniTTS · Hugging Face Space — Text-to-speech that produces emotional, expressive speech from user prompts.
zai-org/GLM-4.6 · Hugging Face — LM with a 200K-token context window, stronger coding/reasoning, and refined writing alignment.
LiquidAI/LFM2-Audio-1.5B · Hugging Face — End-to-end audio foundation model for low-latency, real-time conversation using a FastConformer encoder.
Qwen/Qwen3-VL-235B-A22B-Thinking · Hugging Face — Large vision-language model with improved perception and reasoning for long-context multimodal tasks.
Ming-V2 — an inclusionAI Collection — Curated models for language/audio, including Any-to-Any transforms and audio-editing benchmarks.
openbmb/VoxCPM-0.5B · Hugging Face — Tokenizer-free TTS producing continuous speech reps; context-aware speech and zero-shot voice cloning.
if liked && want_next_issue:
subscribe();📎 Papers
I’ll keep the papers shorter since there are many in this issue. Enjoy!!
You can see more detailed takes here
Boomerang: Distillation Enables Zero-Shot Model Size Interpolation
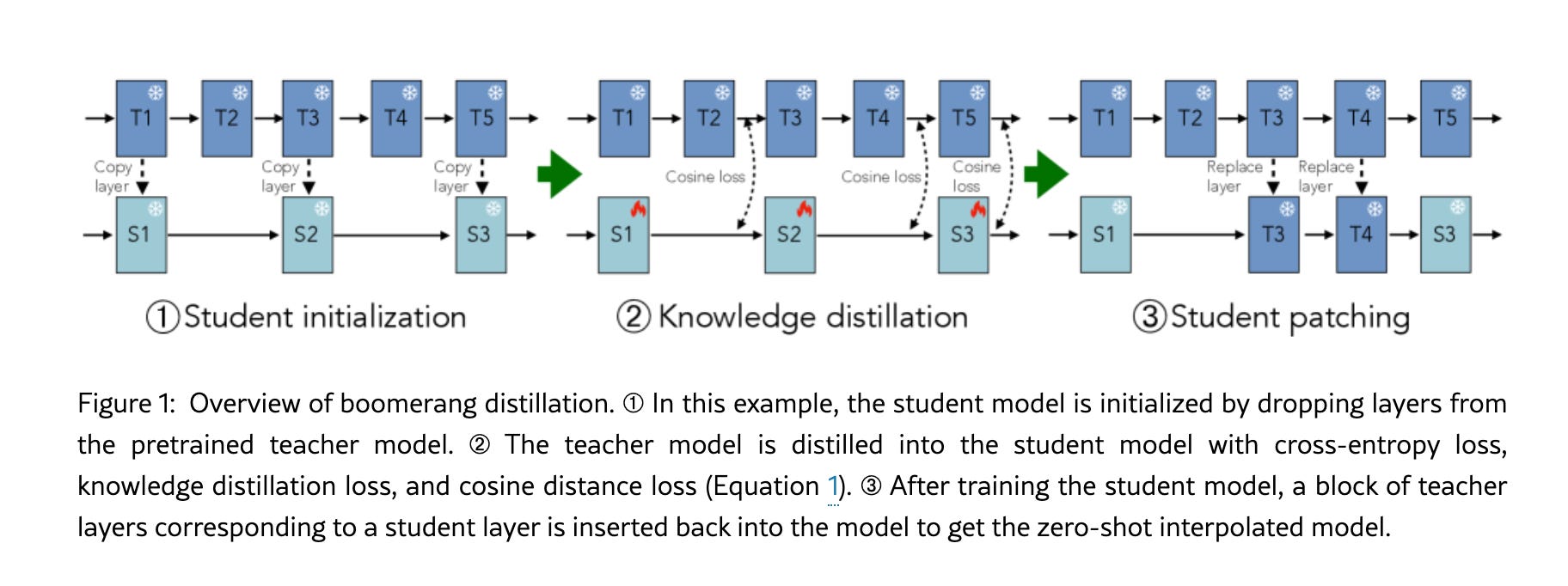
What’s new: “Boomerang distillation” generates intermediate model sizes—without extra training.
How it works: Distill a large teacher into a smaller student, then patch student layers with corresponding teacher blocks to reconstruct intermediate sizes; relies on alignment via pruning and distillation losses (e.g., cosine).
Results: Interpolated models often match or beat pretrained/distilled peers of the same size across Qwen, Pythia, and Llama families; outperforms naive pruning and random interpolation.
Why it matters: Cheaper, faster way to produce fine-grained model families that fit diverse hardware constraints.
TREAD: Token Routing for Efficient Architecture-Agnostic Diffusion Training
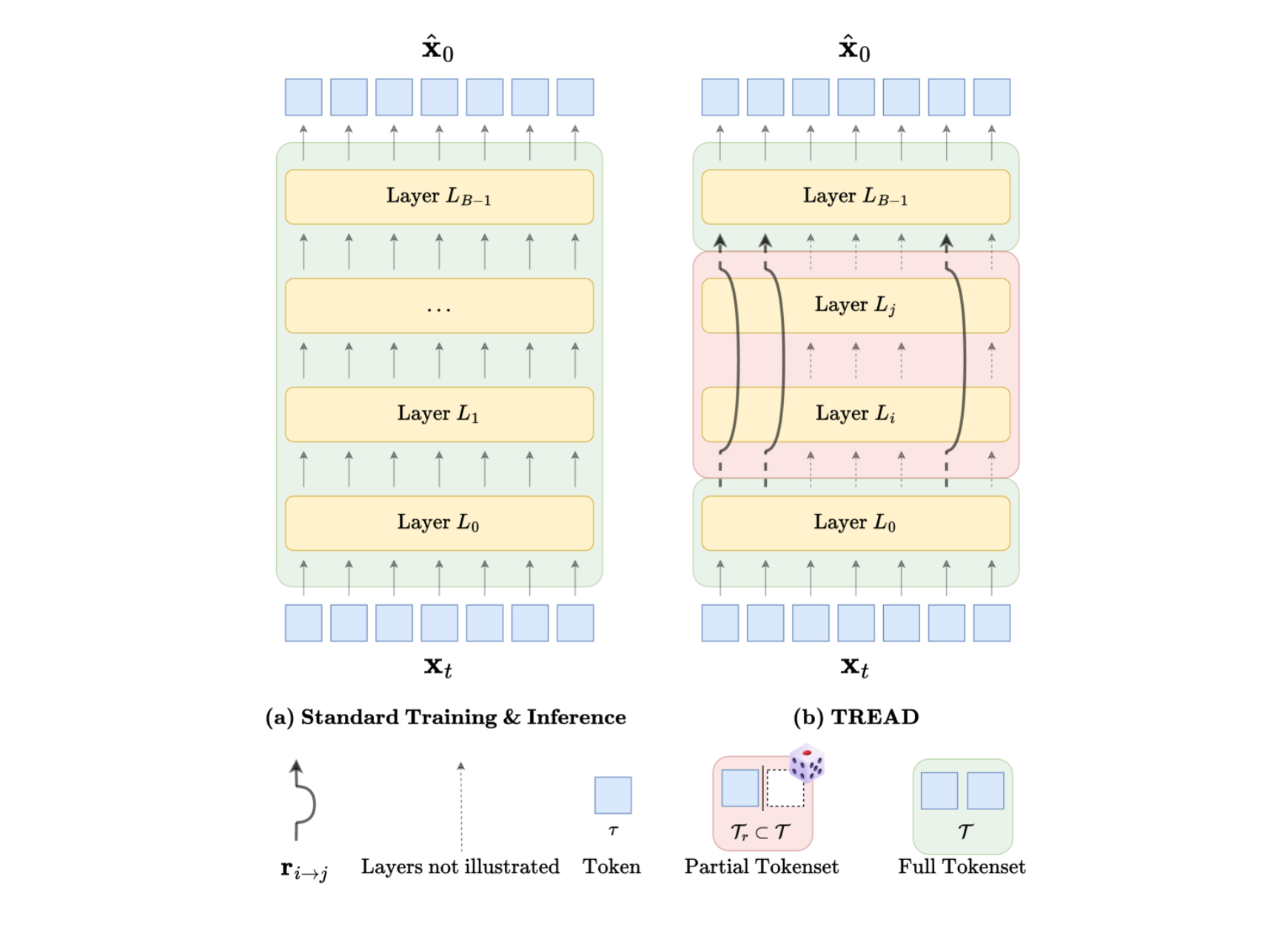
What’s new: Token routing mechanism to cut training cost in diffusion models.
How it works: Transports subsets of early-layer tokens to deeper layers; applies to transformer and state-space models without architectural changes or extra params.
Results: On ImageNet-256, up to 14× faster convergence at 400K iters vs. DiT (37× vs. DiT’s best at 7M iters) with competitive FID (2.09 guided, 3.93 unguided).
Why it matters: Better sample and compute efficiency makes high-quality diffusion training more accessible.
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
What’s new: A memory framework plus Memory-aware Test-Time Scaling (MaTTS) for agents to learn from both successes and failures.
How it works: Distills experiences into structured memories (title/description/content); retrieves relevant items at test time; supports parallel and sequential scaling; uses embedding retrieval.
Results: Up to 34.2% relative effectiveness gains and 16.0% fewer interaction steps across benchmarks; improved generalization across tasks/sites/domains.
Why it matters: Practical path to self-evolving, failure-aware agents.
Training Diffusion Language Models at Scale Using Autoregressive Models
What’s new: A large-scale report on building diffusion language models (RND1) initialized from autoregressive systems.
How it works: Converts AR checkpoints into diffusion-style generators and studies scaling/optimization trade-offs.
Results: Full benchmarks and ablations in the report.
Why it matters: Sharpens understanding of when and how DLMs can rival or complement AR LMs.
MemMamba: Rethinking Memory Patterns in State Space Model
What’s new: Long-sequence architecture with “note-taking” summaries and cross-layer/cross-token attention.
How it works: Stacked MemMamba blocks combine SSM updates, cross-token attention to restore forgotten info, and periodic cross-layer attention; note blocks store high-information tokens.
Results: Outperforms Mamba/Transformers on long-sequence tasks (e.g., PG19, Passkey Retrieval) with ~48% faster inference.
Why it matters: Tackles long-range forgetting while keeping near-linear complexity.
Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking
What’s new: Li² framework decomposes grokking into Lazy, Independent-feature, and Interactive-feature phases; analyzes roles of weight decay, LR, and data.
How it works: Tracks gradient information flow and feature emergence; shows how optimizers (e.g., Muon) diversify hidden units.
Results: Provable scaling laws separating generalization from memorization; experiments validate boundaries across data regimes.
Why it matters: Theory that clarifies when models memorize vs. generalize—and how to steer training.
Artificial Hippocampus Networks for Efficient Long-Context Modeling
What’s new: AHNs maintain a sliding KV cache as lossless short-term memory and compress out-of-window content into fixed-size long-term memory.
How it works: A recurrent module (e.g., Mamba2/DeltaNet/GatedDeltaNet) updates compressed memory as tokens exit the window; constant compute per token.
Results: Beats sliding-window baselines and competes with full attention while cutting FLOPs (~40.5%) and cache size (~74.0%).
Why it matters: A credible recipe for extreme-length contexts without quadratic cost.
Latent Speech-Text Transformer
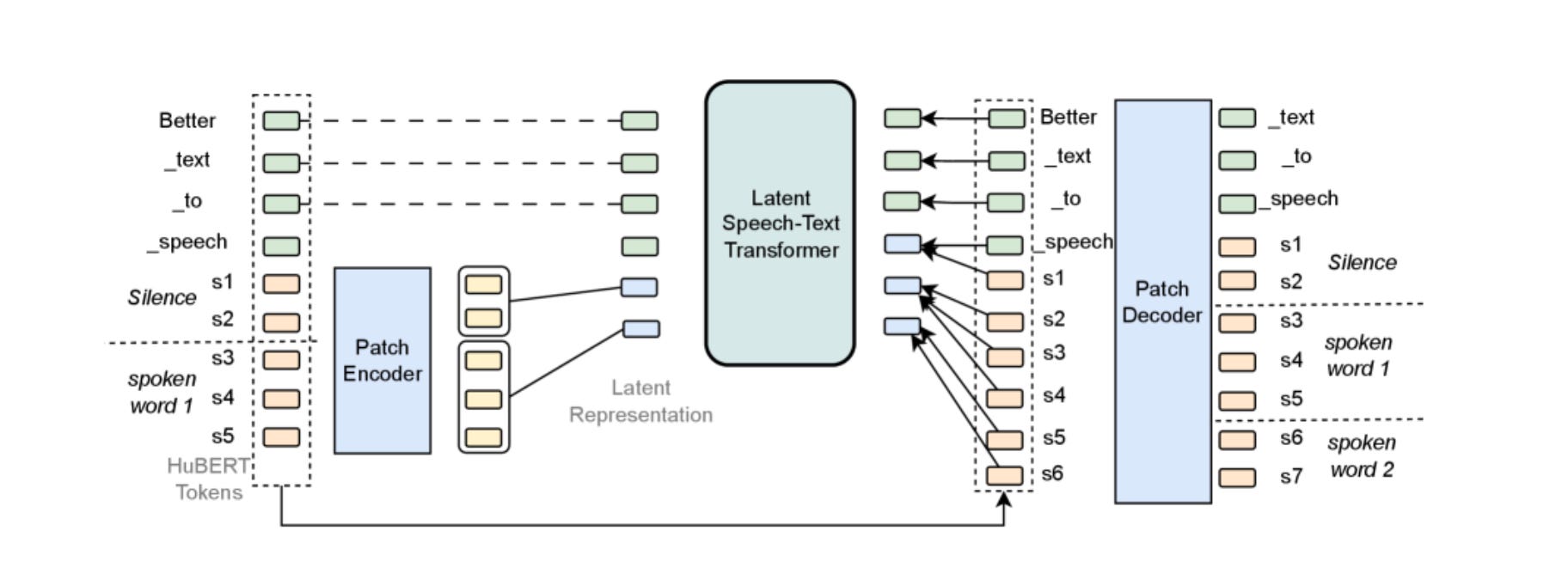
What’s new: LST improves speech-text modeling via latent “patches” for better data efficiency.
How it works: Local encoder aggregates speech tokens into patches; global transformer models interleaved text and patches; lightweight decoder reconstructs speech; supports static, alignment, and curriculum patching.
Results: Gains in speech accuracy (~6.5%) and text performance (~5.3% on HellaSwag); improvements scale from 1B→7B params.
Why it matters: Bridges the information-density gap between speech and text for multi-task learning.
Less is More: Recursive Reasoning with Tiny Networks
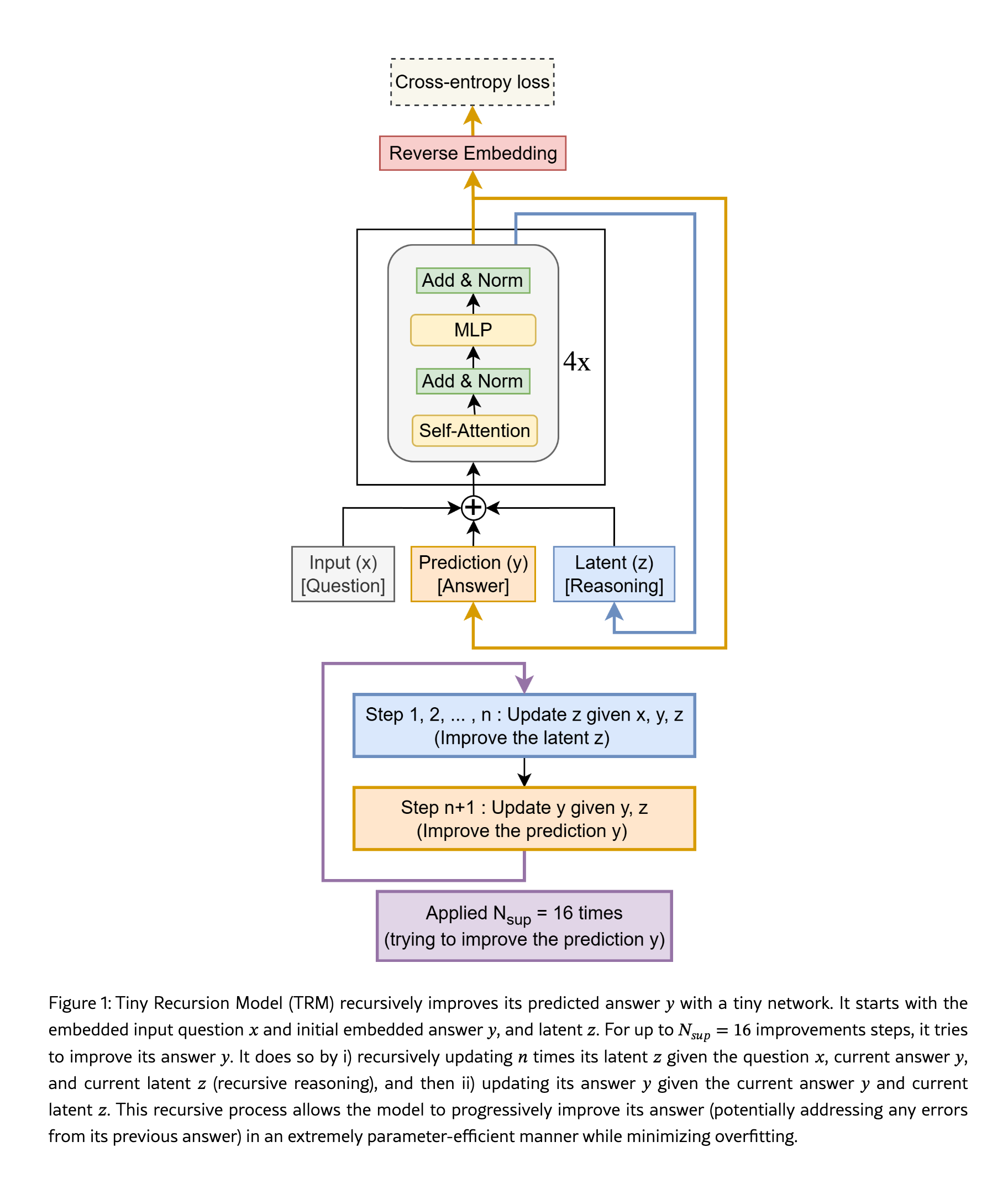
What’s new: Tiny Recursive Model (TRM) uses a 2-layer network to perform recursive reasoning, challenging size-for-quality assumptions.
How it works: Repeatedly evaluates a latent reasoning feature with deep supervision; simplified adaptive compute (ACT) without extra forward passes.
Results: 87.4% on Sudoku-Extreme (vs. HRM’s 55.0%); strong on Maze-Hard and ARC-AGI.
Why it matters: Smaller, simpler reasoning models that generalize—promising for efficient deployment.
My 2 cents: This paper made a buzz last week by beating frontier models on its target tasks. I’d say it’s a better reasoning model than Geminis, GPTs if you want to solve Sudoku. So I guess it is not enough for AGI :)
Ovi: Twin-Backbone Cross-Modal Fusion for Audio-Video Generation
What’s new: Unified, single-pass audio-video generation with twin latent DiTs and bidirectional cross-modal attention.
How it works: A shared T5 encoder conditions matched audio/video towers; two-stage training (audio tower pretraining → cross-modal finetuning); aligned RoPE scales temporal resolution.
Results: High-quality 720×720@24fps clips with superior A/V sync vs. JavisDiT and UniVerse-1.
Why it matters: Treats audio+video as one generative object—cleaner synchronization and scalability.
🧑💻 Open Source
opendatalab/MinerU — Converts complex docs (PDFs, scans) into clean Markdown/JSON for agentic workflows and RAG.
ByteDance-Seed/AHN — Official AHN code: sliding KV + compressed long-term memory for efficient long-context modeling.
zichongli5/NorMuon — Official implementation of the NorMuon paper; reference baselines and experiments.
Thanks for reading… Enjoyed this issue? Share it with a friend.