
Machine Learns #63
New model releases and papers focusing to training tricks, and scaling laws, dLLMs, post-training more...

🤖 Model Releases
💻 Qwen3-Coder-Next — 80B-parameter text generation model optimized for coding and language tasks.
from machine_learns import newsletter
newsletter.subscribe(frequency="bi-weekly")🎭 MiniCPM-o 4.5 — 9B-parameter multimodal model for real-time, full-duplex audio and video processing with bilingual speech conversation and advanced visual capabilities.
🔊 MMS-300M Forced Aligner — Python package for efficient forced alignment of text and audio using Hugging Face pretrained models, with improved memory usage over TorchAudio.
🎬 LingBot-World — Open-source world simulator for video generation featuring high-fidelity environments, long-term memory, and real-time interactivity.
💻 Step 3.5 Flash — Open-source sparse MoE foundation model for efficient reasoning and agentic tasks, processing 100–300 tokens/sec with 256K context window.
🗣️ KugelAudio-0-Open — Open-source TTS model for European languages with voice cloning, using a 7B-parameter AR + Diffusion architecture trained on ~200K hours of speech.
👂 Qwen3-ASR — Open-source ASR series from Alibaba Cloud supporting multilingual speech, music, and song recognition with language detection and timestamp prediction.
🖼️ Z-Image — 6B-parameter single-stream diffusion transformer for efficient image generation, editing, and bilingual text rendering.
🎭 Kimi-K2.5 — Image-text-to-text model from Moonshot AI built on the Transformers library.
💻 Stable-DiffCoder-8B-Instruct — Code diffusion LLM built on Seed-Coder architecture with block diffusion continual pretraining for improved code generation, reasoning, and editing.
🗣️ LuxTTS — Lightweight TTS model for voice cloning achieving 150x+ realtime speed while fitting in 1GB VRAM.
🎬 Linum v2 — Open-weight 2B-parameter text-to-video model generating 2–5 second clips at up to 720p for experimentation in generative media.
👂 VibeVoice-ASR — Unified speech-to-text model processing up to 60 minutes of long-form audio in a single pass with speaker identification, timestamps, and user-customized context support.
📎 Papers
🧠 A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
What’s new
A framework explaining outlier-driven rescaling in transformers, identifying attention sinks and residual sinks as functional components rather than artifacts. Proposes GatedNorm and PreAffine methods to mitigate outliers while preserving performance.
How it works
Outliers interact with normalization mechanisms (softmax and RMSNorm) to rescale non-outlier components
Attention sinks: specific tokens receive disproportionately high attention scores
Residual sinks: fixed dimensions exhibit consistently high activations across tokens
GatedNorm: element-wise low-rank self-gating after normalization layers
PreAffine: learnable scaling vector before normalization to enable outlier-driven rescaling without large residual values
Results
Improved training stability and performance across various models
Enhanced quantization robustness under aggressive low-bit settings
Gains in knowledge, reasoning, STEM, code generation, and multilingual tasks
🌫️ Causal Autoregressive Diffusion Language Model

What’s new
Unifying the training efficiency of autoregressive models with high-throughput inference of diffusion models.
How it works
Strictly causal attention mask reformulates the diffusion process
Shifted causal attention where each position predicts its original token from preceding noised context
Dense supervision for entire sequences in a single forward pass
Soft tail masking concentrates noise at the sequence tail
Context-aware reweighting adjusts loss weights based on local ambiguity
Dynamic parallel decoding with KV-caching generates variable-length sequences based on confidence
Results
Outperforms existing discrete diffusion models by 5.7+ points in zero-shot accuracy
ARM-level data efficiency with 3× reduced training latency vs. block diffusion methods
Lowest zero-shot perplexity across multiple domains
🧠 Residual Context Diffusion Language Models
What’s new
A mechanism that recycles computation from discarded low-confidence tokens instead of discarding them at every denoising steps to improve dLLM accuracy.
How it works
Transforms discarded token representations into contextual residuals for the next denoising step
Two-stage training: lightweight reference model generates reliable probability distributions; target model incorporates residuals using reference model as stable guide
Entropy-based embedding aggregation selects and aggregates context
Dynamically adjusts residual contribution based on normalized Shannon entropy
Results
5–10 point accuracy improvement on various benchmarks with minimal extra computation
Nearly doubles baseline accuracy on challenging AIME tasks
Reduces denoising steps by 4–5× at equivalent accuracy levels
🧷 Scaling Embedding Layers in Language Models
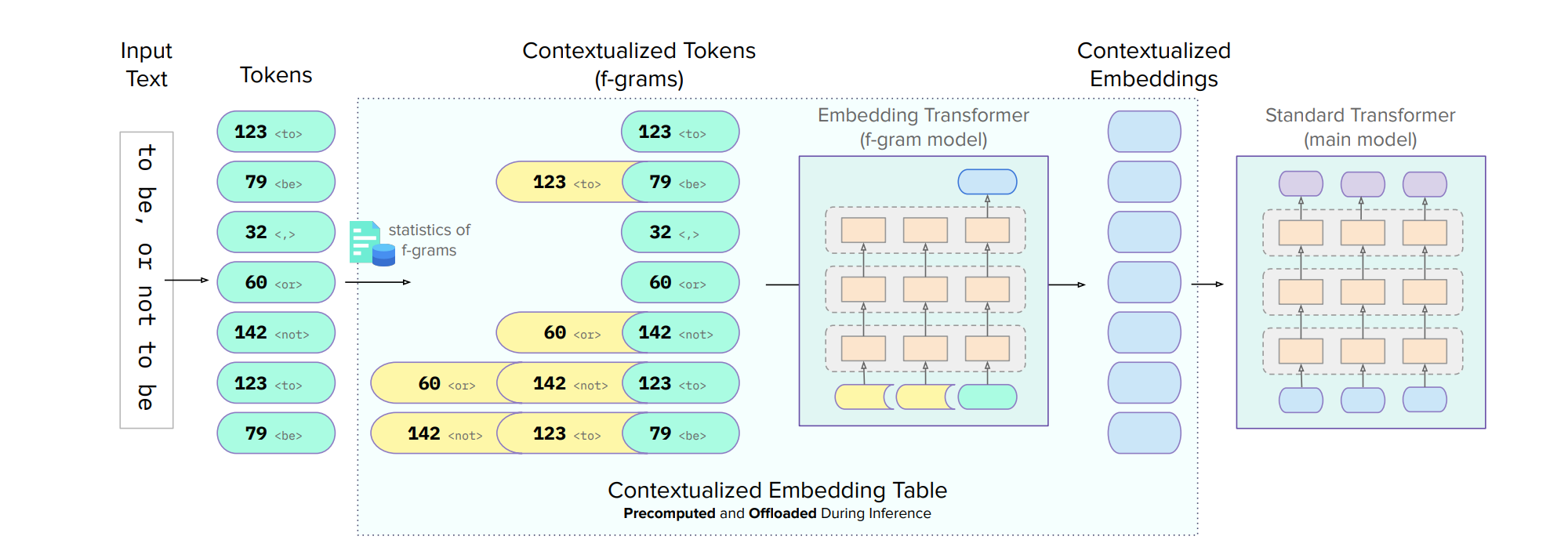
What’s new
Scone (Scalable, Contextualized, Offloaded, N-gram Embedding), a method enhancing input embeddings without increasing decoding costs.
How it works
Retains original vocabulary while adding embeddings for frequent n-grams
Separate transformer (f-gram model) learns contextualized representations
Embeddings precomputed and stored in off-accelerator memory
Avoids sparse update problem by parameterizing embeddings with f-gram model
F-gram layer can be offloaded, maintaining fixed accelerator resources during inference
Results
1B accelerator-resident parameter model outperforms 1.9B baseline
Uses approximately half the FLOPs and accelerator memory during inference
🏗️ ConceptMoE: Adaptive Token-to-Concept Compression
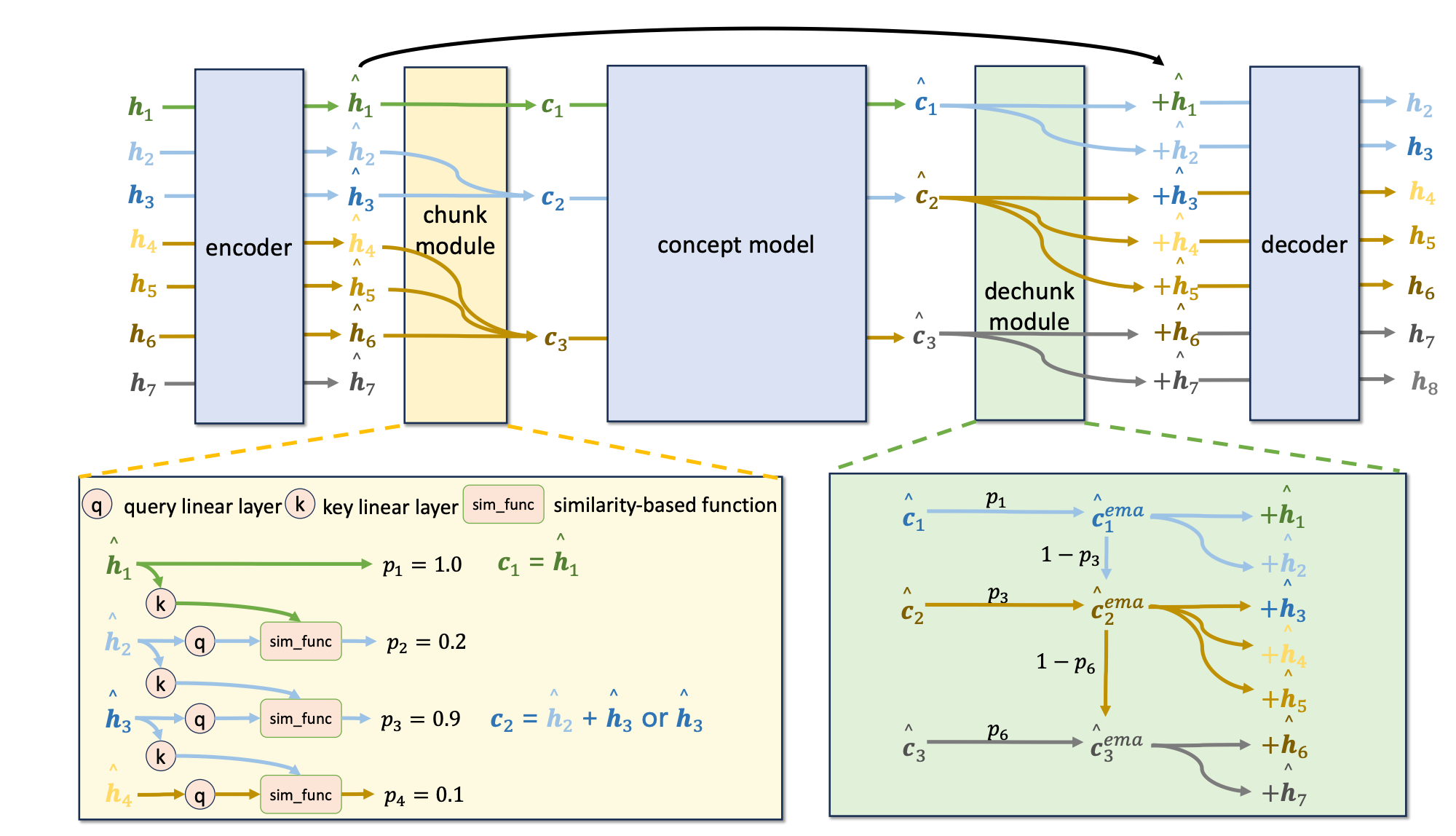
What’s new
Adaptive token-to-concept compression for implicit compute allocation, dynamically merging semantically similar tokens within MoE architectures.
How it works
Learnable chunk module identifies boundaries based on inter-token similarity
Consecutive high-similarity tokens merge into concept representations
MoE architecture enables controlled evaluation by reallocating saved computation
Minimal architectural changes for straightforward integration
Results
+0.9 points on language pretraining, +2.3 on long context understanding, +0.6 on multimodal benchmarks
+5.5 points when converting pretrained MoE during continual training
Prefill speedups up to 175%, decoding speedups up to 117%
🏗️ TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon
What’s new
A generalization of the Muon optimizer extending orthogonalization beyond individual layers for LLM pre-training.
How it works
Models gradients as structured higher-order tensors
Performs matrix-level gradient orthogonalization across layers simultaneously
Provides improved convergence guarantees over layer-wise Muon
Robust under different approximate SVD schemes
Results
Evaluated on GPT-style (130M–774M) and LLaMA-style (60M–1B) models
Consistently improves training and validation perplexity across scales
🔊 High-Fidelity Generative Audio Compression at 0.275kbps
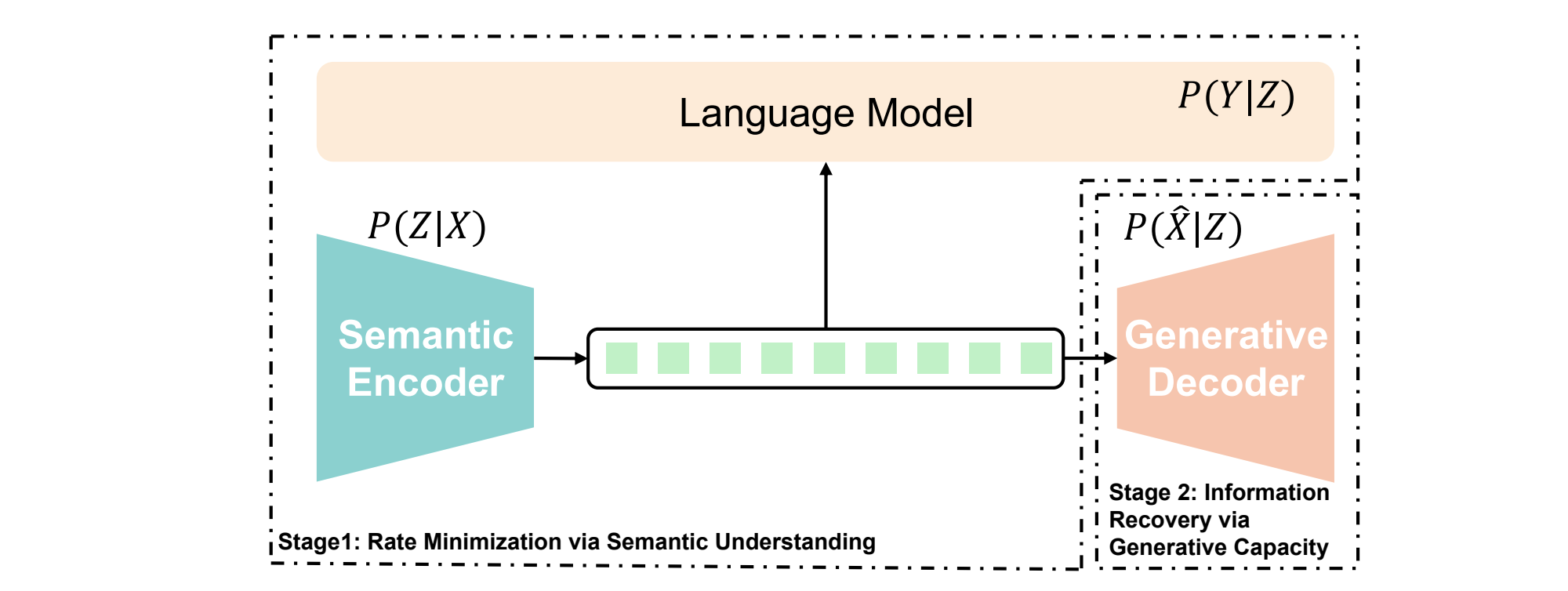
What’s new
Achieving high-fidelity audio at ultra-low bitrates (0.275kbps), shifting from signal fidelity to task-oriented effectiveness.
How it works
Integrates semantic understanding at the transmitter with generative synthesis at the receiver
Two-stage process: learns compressed semantic representation aligned with linguistic supervision, then recovers high-fidelity audio via large generative model
Encoder filters redundancy, transmitting only semantic essence
Decoder reconstructs details from model priors
Results
High-fidelity 32kHz audio reconstruction at 0.275kbps with 3000× compression ratio
Outperforms SOTA neural codecs in perceptual quality and semantic consistency
Maintains intelligible transmission even at 0.175kbps
🔊 SemanticAudio: Audio Generation and Editing in Semantic Space
What’s new
A two-stage Flow Matching framework (Semantic Planner + Acoustic Synthesizer) for audio generation and editing in high-level semantic space with training-free text-guided editing.
How it works
Semantic Planner: generates compact semantic features from text using dual inputs (global sentence embedding + token-level embeddings)
Acoustic Synthesizer: produces high-fidelity acoustic latents conditioned on semantic features
Editing: delta velocity fields from source/target prompts enable semantic-level modifications without retraining
Results
Superior semantic alignment (CLAP score 0.354)
High reconstruction fidelity with low Mel and STFT loss
Robust editing capabilities even without source text
🎬 Memory-V2V: Augmenting Video-to-Video Diffusion Models with Memory
What’s new
A framework for multi-turn video editing with cross-consistency, using explicit memory to enhance video-to-video diffusion models.
How it works
Lightweight memory modules integrate into V2V models
Dynamic tokenization with varying kernel sizes based on edit relevance
Retrieval mechanism identifies relevant past edits from external cache
Learnable token compressor reduces redundancy while preserving visual cues (30% speedup)
Results
Strong cross-iteration consistency in novel view synthesis and text-guided long video editing
Outperforms SOTA baselines in visual quality and computational efficiency
🔁 Self-Distillation Enables Continual Learning
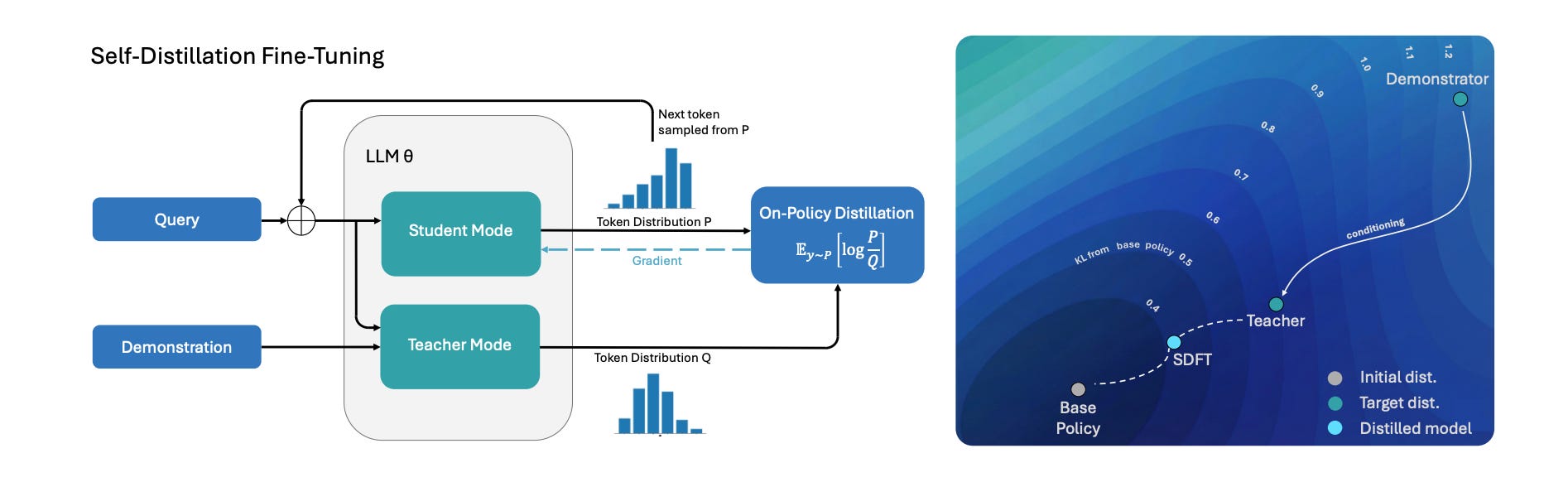
What’s new
Self-Distillation Fine-Tuning for continual learning, enabling on-policy learning directly from expert demonstrations.
How it works
Single model serves as both teacher and student.
Teacher conditioned on task [prompt + example demonstration]; student uses only the prompt
Training minimizes reverse KL divergence between teacher and student outputs
Model learns from own generated trajectories while preserving prior capabilities
Results
Higher new-task accuracy and better retention than SFT
Single model acquires multiple skills sequentially without performance degradation
Outperforms baselines on both in-distribution and out-of-distribution tasks
🔁 Teaching Models to Teach Themselves
What’s new
SOAR, a self-improvement framework using meta-RL where a teacher model generates automated curricula for problems the student cannot yet solve.
How it works
Optimization with outer Teacher and inner Student loop stages.
Teacher proposes synthetic problems for inner looper Student optimization.
After N inner loops steps, Teacher is rewarded based on Student’s improvement. (Teacher learns to teach in the outer looper)
Both stages uses RLOO for optimization.
Results
Bi-level meta-RL facilitates learning despite sparse rewards
Structural quality of generated questions more important than solution correctness
🔁 Recursive Self-Aggregation Unlocks Deep Thinking in LLMs
What’s new
Combining parallel and sequential scaling methods to improve LLM reasoning.
How it works
Maintains population of candidate solutions at each step
Aggregates subsets to iteratively produce improved solutions
Inspired by evolutionary algorithms, enables model to revisit and correct reasoning
RL training teaches effective solution aggregation
Results
Significant performance improvements across tasks vs. traditional methods
Bridges gap between smaller and larger reasoning models
🔁 Training-Free Group Relative Policy Optimization
What’s new
A method enhancing LLM performance without parameter updates by leveraging experiential knowledge as token priors.
How it works
Uses group-based rollouts to distill semantic advantages from multiple outputs
Maintains frozen model; updates external experiential knowledge library
Each step: generate outputs, score them, extract semantic advantages based on performance
Adapts to new scenarios with minimal training data
Results
Significant improvements in mathematical reasoning and web searching
Outperforms fine-tuned models with fewer samples and lower costs
Strong performance on AIME24, AIME25, and WebWalkerQA
🧑💻 Open Source
FastGen — NVIDIA library for fast generation from diffusion models.
Enjoyed this issue? Send it to a friend who’d appreciate it.