
Machine Learns - 64
StepFun’s frontier reasoning MoE to unified audio LLMs and multilingual TTS that beats ElevenLabs. Plus: sparse attention breakthroughs, 2-bit video generation...

🤖 Model Releases
🎙️ Ming-omni-tts-0.5B — Voice core of Ming-flash-omni-2.0: 0.5B TTS model with voice cloning from inclusionAI (Ant Group).
from machine_learns import newsletter
newsletter.subscribe(frequency="bi-weekly")🤖 JoyAI-LLM-Flash-Base — State-of-the-art MoE LLM (3B activated) optimized for agents and high throughput.
🌐 Ming-flash-omni 2.0 — Open-source SOTA omni-MLLM (100B total / 6B active MoE): multimodal understanding + speech/audio/music synthesis + image generation/editing in one model.
🎙️ MOSS-TTS — Open-source TTS family with high-fidelity zero-shot voice cloning, controllable long-form synthesis (up to 60 min), multilingual support, and multi-speaker dialogue generation (5 speakers).
📱 HY-1.8B-2Bit — Tencent AngelSlim’s 2-bit QAT of Hunyuan-1.8B-Instruct. Only 4% degradation vs. full precision, outperforms 0.5B dense models by 16%. GGUF format for edge deployment.
🧠 Step 3.5 Flash — StepFun’s open-source frontier reasoning MoE: 196B total / 11B active per token. 3-way MTP for 100–350 tok/s. 74.4% SWE-bench, 256K context. Rivals top proprietary models; runs on Mac Studio M4 Max.
🎙️ KugelAudio — Open TTS model for 24 European languages trained on 200K hours of YODAS2 data. Built on Microsoft VibeVoice with voice cloning. Beats ElevenLabs in human preference testing.
🔬 OpenResearcher — 30B-A3B MoE model + 96K DeepResearch trajectories + 11B-token corpus + benchmarks. Fully open deep research agent by TIGER-Lab.
🎵 UniAudio 2.0 — Unified audio language model using discrete audio codec for text-aligned representation with autoregressive architecture for multi-task training across diverse audio tasks.
📎 Papers
🧠 LCM: Lossless Context Management
What’s new
A lossless context management framework that preserves full data integrity while enabling efficient information retrieval in LLMs.
How it works
Uses AI-driven techniques for context management
Employs lossless compression to preserve complete data integrity
Integrates a tagging system for efficient information retrieval
Enhances user interaction with contextual data through structured organization
Results
Not specified in paper
Why it matters
Addresses key challenges in data management for long-context applications and could improve AI systems across various domains.
🎵 MOSS-Audio-Tokenizer: Scaling Audio Tokenizers for Future Audio Foundation Models
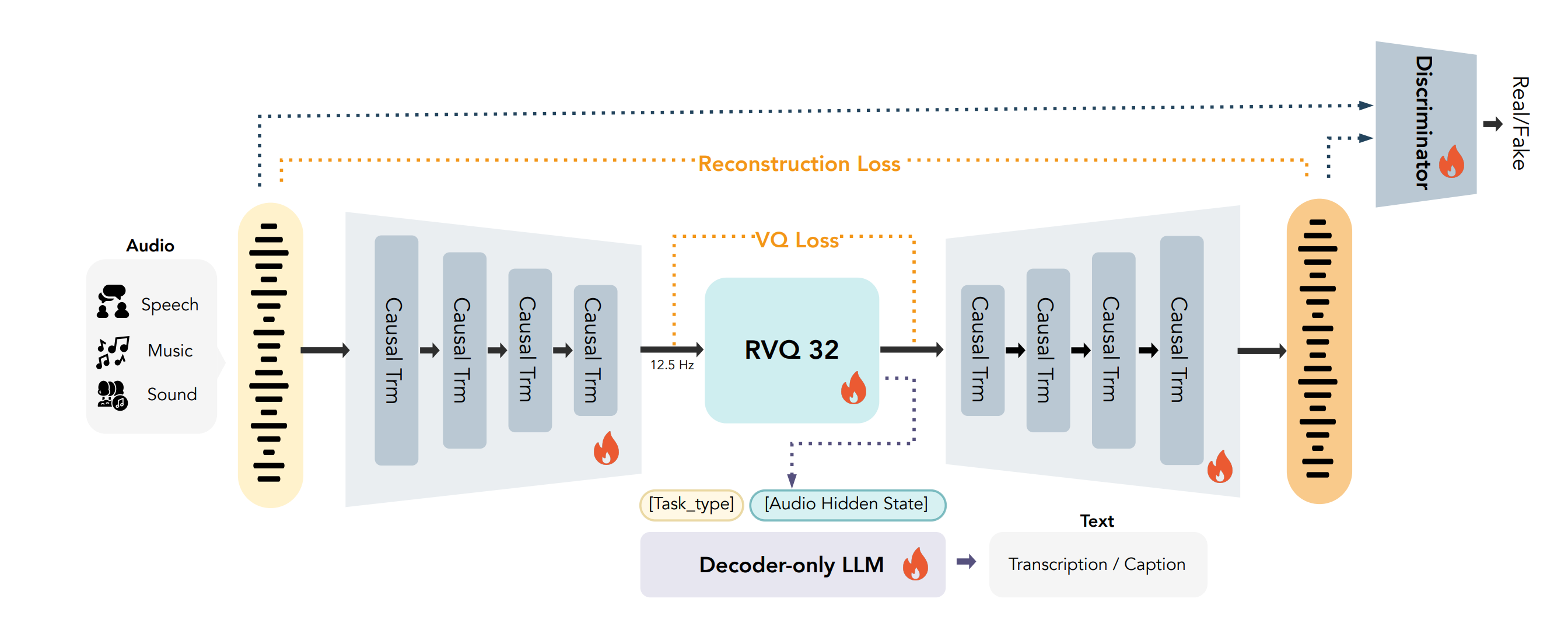
What’s new
A large-scale audio tokenizer (1.6B parameters) using a fully end-to-end learning approach with a homogeneous architecture.
How it works
CAT (Causal Audio Tokenizer with Transformer) architecture
Jointly optimizes encoder, quantizer, and decoder from scratch
Purely Transformer-based design for high-fidelity audio reconstruction
Scales well across speech, sound, and music domains
Results
Outperforms prior codecs across various bitrates for audio reconstruction
First autoregressive TTS model to surpass non-autoregressive and cascaded systems on similarity metrics.
Competitive ASR performance without auxiliary encoders
My 2 cents
Best discrete codec I’ve tried for the given bitrate wrt both semantic and acoustic reconstruction.
📦 Proxy Compression for Language Modeling
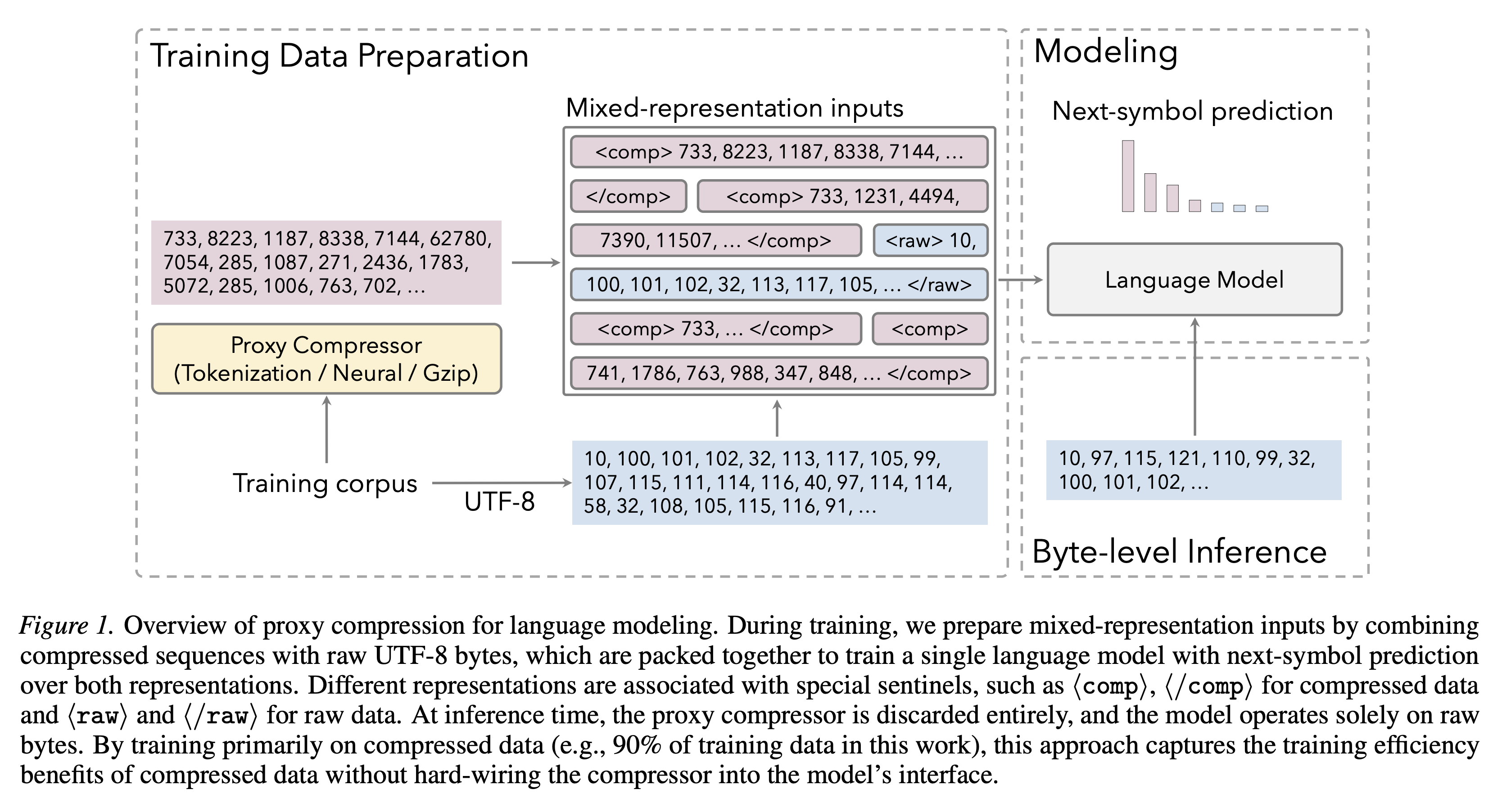
A mixed-representation training that uses external compressors (tokenizer, neural, gzip) only as a training-time proxy, then discards them for pure byte-level inference.
How it works
Jointly trains one autoregressive LM on raw UTF-8 bytes (10%) and compressed views (90%) packed into the same contexts
Special tokens (⟨raw⟩/⟨comp⟩) informs the model what representation it takes in
In-context translation pairing during warmup: both views of the same sample in one context to bootstrap cross-representation alignment
Three proxy compressors tested: BPE tokenizer (~3.7× compression), neural arithmetic coder (~2.6×), and gzip (~2.5×)
Neural compressor uses entropy-based segmentation for parallel encoding; produces “fuzzy” many-to-one mappings where collisions only differ in low-entropy details (whitespace, indentation)
Results
At 14B scale, proxy-trained models match or surpass tokenizer-based baselines on HumanEval-Plus and MBPP-Plus — while running on raw bytes
Transfer strength scales with model size: weak/negative at 0.5B, competitive at 4B, surpassing at 14B
gzip fails as a proxy (negative transfer) due to unstable output under small input perturbations
Proxy models retain byte-level robustness: best Robust Pass@1 (19.8) vs. tokenizer baseline (14.9) on ReCode
🎵 STACodec: Semantic Token Assignment for Balancing Acoustic Fidelity and Semantic Information
What’s new
Semantic Token Assignment (STA) for audio codecs that decouples semantic structure from acoustic representation.
How it works
Uses semantic token indices from K-means on SSL models (WavLM/HuBERT) as RVQ-1 code indices - just indices not the real embeddings
Yet it learns RVQ-1 codebook embeddings for acoustic reconstruction from scratch.
Semantic Pre-Distillation (SPD) predicts semantic tokens before quantization
SPD employs random masking (temporal + feature dimensions) to reduce overfitting
Eliminates the SSL model at inference.
Results
ViSQOL score of 4.51 and WER of 9.35%
Balanced codebook utilization across all RVQ layers
🎙️ PFluxTTS: Hybrid Flow-Matching TTS with Robust Cross-Lingual Voice Cloning
What’s new
A hybrid flow-matching TTS system with robust cross-lingual voice cloning and inference-time model fusion.
How it works
Uses flow-matching for text-to-speech synthesis
Implements voice cloning that adapts across languages
Uses two decoder models; duration-guided model and alighment-free model
Interpolates outputs from 2 decoder models at inference time for better quality and consistency.
Results
Improved voice quality and naturalness in TTS outputs
Enhanced cross-lingual voice cloning capability
⚡ HySparse: Hybrid Sparse Attention with Oracle Token Selection and KV Cache Sharing
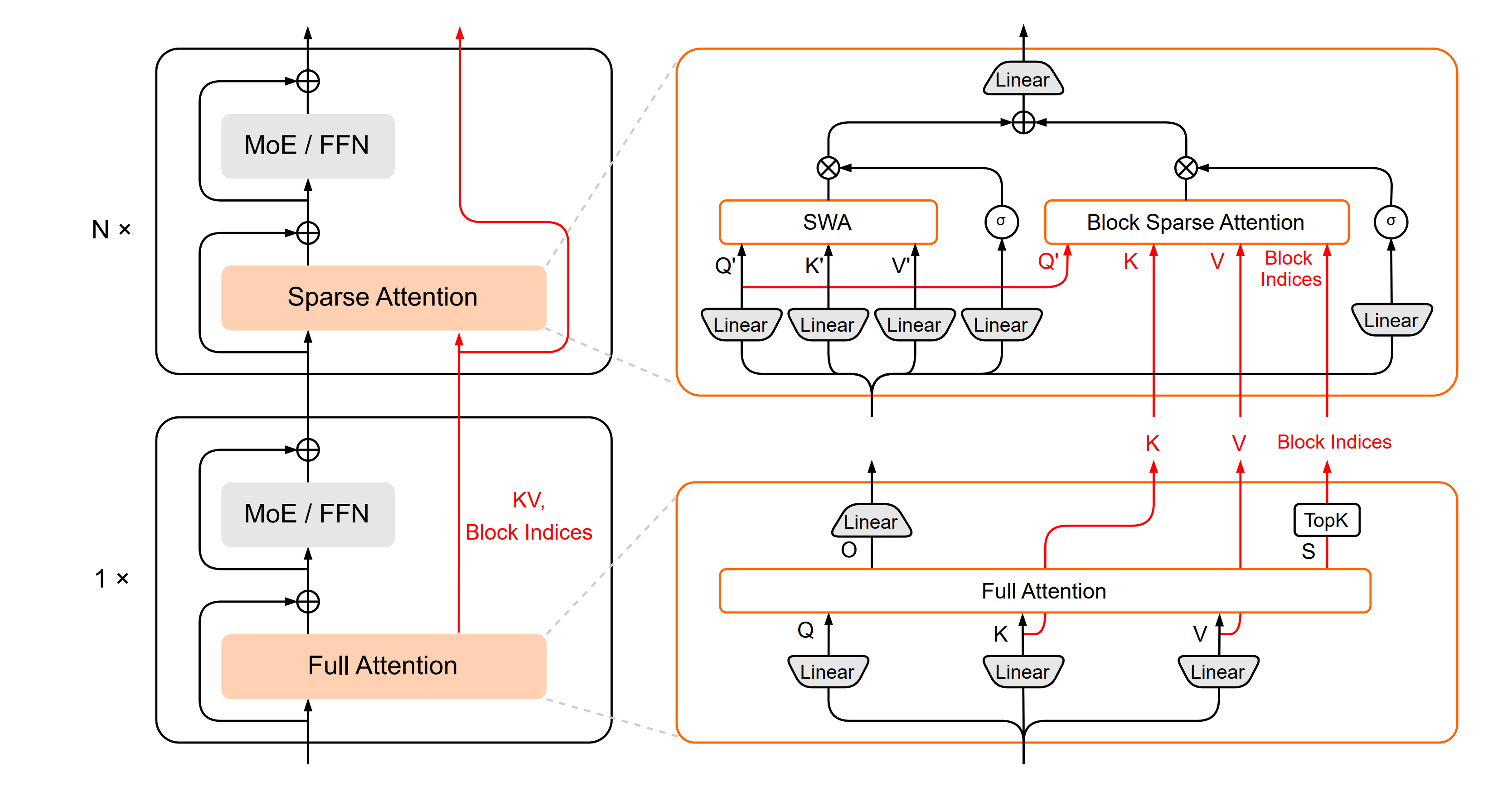
What’s new
A hybrid sparse attention architecture that interleaves full attention layers with sparse attention layers, using oracle token selection and cross-layer KV cache sharing.
How it works
Interleaves full attention layers with multiple sparse attention layers
Full attention layers identify important tokens and produce KV caches
Sparse layers reuse token indices and KV caches from preceding full attention layers
Uses block-level maximum attention scores for efficient TopK selection
Two branches: Block Sparse Attention (reuses KV) + Sliding Window Attention (local KV cache)
Sigmoid gates fuse outputs from both branches
Cross-layer KV cache sharing reduces memory footprint
Results
Outperforms full attention and hybrid SWA baselines
Achieves significant KV cache reduction while maintaining performance
In 80B MoE model, only 5 of 49 layers use full attention
🎬 Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
What’s new
A training-free KV-cache quantization framework for auto-regressive video generation that leverages video-specific spatiotemporal redundancy.
How it works
Semantic-Aware Smoothing: Groups semantically similar tokens via k-means clustering, producing quantization-friendly residuals
Progressive Residual Quantization: Multi-stage scheme that progressively refines residuals from coarse to fine granularity
KV-Cache Management: Quantizes KV-cache (which grows linearly with tokens), reducing memory up to 7× while maintaining quality
Introduces minimal latency overhead (1.5%–4.3%)
Results
Outperforms SOTA KV-cache quantization baselines
Up to 6.94× compression ratio with near-lossless quality
Enables long video generation on limited hardware (e.g., HY-WorldPlay-8B on single RTX 4090)
🧑💻 Open-Source
🐍 pydantic/monty — A minimal, secure Python interpreter written in Rust for use by AI.
🗄️ alibaba/zvec — A lightweight, lightning-fast, in-process vector database.
Thanks for reading… Enjoyed this issue? Share it with a friend. 👍