
Machine Learns - 65
This week: Causal diffusion meets interpretability with Steerling-8B, speculative decoding gets faster with LK Losses, and a unified framework tackles human-centric audio-video generation.

🤖 Model Releases
🧠 Steerling-8B — 8B parameter causal diffusion language model that generates text by iteratively unmasking tokens and decomposing internal representations into interpretable concepts.
from machine_learns import newsletter
newsletter.subscribe(frequency="bi-weekly")📄 FireRed-OCR-2B — 2B OCR model using GRPO to eliminate structural hallucinations in tables and LaTeX.
💻 Jan-Code-4B — 4B compact open coding model by Jan (janhq), distilled from a larger teacher, optimized for local/desktop use and tool calling via Jan Desktop or vLLM.
📎 Papers
🎨 CMT: Consistency Mid-Training for Efficient Learning of Flow Map Models
What’s new
A lightweight intermediate training stage between diffusion model pre-training and flow map post-training (e.g., Consistency Models or Mean Flow).
How it works
A pre-trained diffusion model generates reference ODE trajectories by running a solver from noise to clean data.
CMT trains the student to regress any intermediate point on that trajectory to the clean endpoint (output of the teacher). Simple, fixed-target regression with no stop-gradients or ad-hoc heuristics.
Mid-trained weights initialize the actual flow map post-training (ECT, ECD, or MF), which converges faster and more stably.
Works with both Consistency Model and Mean Flow parameterizations; architecture-agnostic. A small teacher can bootstrap a much larger student.
Results
SOTA 2-step FIDs: 1.97 (CIFAR-10), 1.32 (ImageNet 64×64), 1.84 (ImageNet 512×512).
Up to 98% reduction in training data budget compared to prior consistency model methods.
Removes tricks like σ-annealing, custom time sampling, loss reweighting, and special EMA schedules.
⚡ LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
What’s new
New training objectives for speculative decoding that directly optimize acceptance rate instead of using KL divergence as a proxy. Two variants: a likelihood-based loss (negative log acceptance rate) and a hybrid loss that adaptively blends KL with Total Variation distance (TV).
How it works
Standard draft model training minimizes KL divergence, but when draft models have limited capacity (1–5% of target params), KL’s global optimum is unreachable, and minimizing KL ≠ maximizing acceptance rate at suboptimal points.
TV distance directly equals 1 − acceptance_rate, but has vanishing gradients and non-smooth landscape from random init (gradient norm scales as O(1/|V|)).
The hybrid loss ℒ_LKλ starts KL-dominated (smooth gradients) and adaptively shifts to TV-dominated as acceptance improves, using α = exp(−η·acceptance_rate) scheduling. Analogous to trust-region methods.
The likelihood-based loss ℒ_LKα = −log(acceptance_rate) provides TV-direction gradients with automatic 1/α scaling that prevents vanishing gradients.
Handles truncated vocabularies naturally. TV/acceptance targets the original distribution, unlike KL which needs a modified target.
Results
Consistent gains across 4 draft architectures (EAGLE-3, MLP speculator, MEDUSA, DeepSeek MTP) and 6 target models (8B to 685B params).
Up to 8–10% improvement in average acceptance length.
Largest gains on low-capacity drafters and large MoE targets (7.7% on GPT-OSS 120B, 8.2% on Qwen3-235B).
DeepSeek-V3 MTP fine-tuning: +5.6% over KL at temp=1.
Pure TV training fails badly from random init, confirming the gradient analysis.
Why it matters
Drop-in replacement for KL loss in any speculative decoding training pipeline. No computational overhead. Especially impactful when draft-target capacity gap is large (the common real-world scenario).
🧠 MLRA: Multi-Head Low-Rank Attention
What’s new
Decomposes MLA’s single latent KV head into multiple independent latent heads, enabling native 4-way tensor parallelism for decoding. Something MLA fundamentally can’t do because its single latent head can’t be shared.
How it works
MLA compresses KV cache into a single latent head and absorbs up-projection into queries during decoding. But since the latent head can’t be partitioned, every TP (Tensor Parallelism) device must redundantly load the full KV cache.
MLRA-4 splits the latent head into 4 blocks, independently up-projects each to form NoPE keys/values, computes attention separately per block, and sums the outputs. Each block is independently assignable to a TP device.
Variance calibration scales query/KV latent states to fix the variance mismatch between NoPE and RoPE components (originally noted by LongCat), and rescales attention outputs after multi-branch summation.
Uses zero initialization for output projections (from muP/LoRA insight) and optionally adds gating before output projection.
Results
At 2.9B scale on FineWeb-Edu-100B: MLRA-4 achieves best avg perplexity (13.672 vs 13.727 MLA, 14.139 GQA) and best zero-shot reasoning (58.84% vs 58.75% MLA).
2.8× decoding speedup over MLA with 4-way TP.
1.05–1.26× speedup over GQA in long-context decoding (128K–2M tokens).
With gating: MLRA-4 reaches 13.621 avg perplexity.
Why it matters
Solves MLA’s fundamental TP bottleneck.
💾 Untied Ulysses: Memory-Efficient Context Parallelism via Headwise Chunking
What’s new
Context parallelism via headwise chunking, processes U attention heads at a time instead of all H, reducing peak activation memory up to 87.5% while matching Ulysses throughput. Trains 5M-token sequences on a single 8×H100 node.
How it works
Splits multi-head attention into U-head stages, reusing activation buffers across stages. When U equals the chunk count C, peak memory becomes independent of total head count.
GQA-compatible scheduling reuses KV heads across grouped queries.
Drop-in replacement for Ulysses and compatible with FlashAttention kernels and USP hybrid parallelism.
Results
Llama3-8B: 5M-token sequences (25% beyond FPDT’s limit); 8M tokens on 16×H100 (33% beyond USP-Hybrid).
Qwen3-32B: 4M-token sequences (2× Ulysses baseline).
87.5% attention activation memory reduction for 32B-class models.
Why it matters
Makes million-token training practical on commodity multi-GPU nodes without model-parallel overhead.
🔬 Spectral-Decoupled MoE: Are MoE Gated Experts Just Fake Experts Trapped in Low-Rank Swamp?
What’s new
Questions whether gated experts in standard MoE models are “fake experts” trapped in a low-rank subspace, and proposes Spectral-Decoupled MoE to fix it.
How it works
Analyzes the spectral (singular-value) structure of learned expert weight matrices and shows standard gating collapses experts into near-identical low-rank representations.
Decouples the spectral components of expert weights so each expert can span a richer, more diverse subspace, preventing redundant experts.
Training-time gradient decomposition:
- Project the gradient update onto the shared low-rank subspace → update the shared/common parameters
- The residual gradient (orthogonal part) updates the unique expert parameters
Results
Inter-expert similarity in dominant subspaces drops dramatically (they cite ~0.1 vs ~0.7/0.9 in baselines).
Downstream performance: ~3% gains reported.
Training efficiency: ~30% improvement reported.
Overhead: ~5% extra compute, designed to plug into existing MoEs (including Qwen/DeepSeek).
Why it matters
If MoE experts converge to similar low-rank solutions, the capacity gain from adding more experts is illusory and you’re paying the routing and memory cost for near-duplicate weights. Spectral decoupling could unlock the full parameter-efficiency MoE architectures promise, especially at scale.
🎵 DashengTokenizer: One Layer is Enough for Unified Audio Understanding and Generation
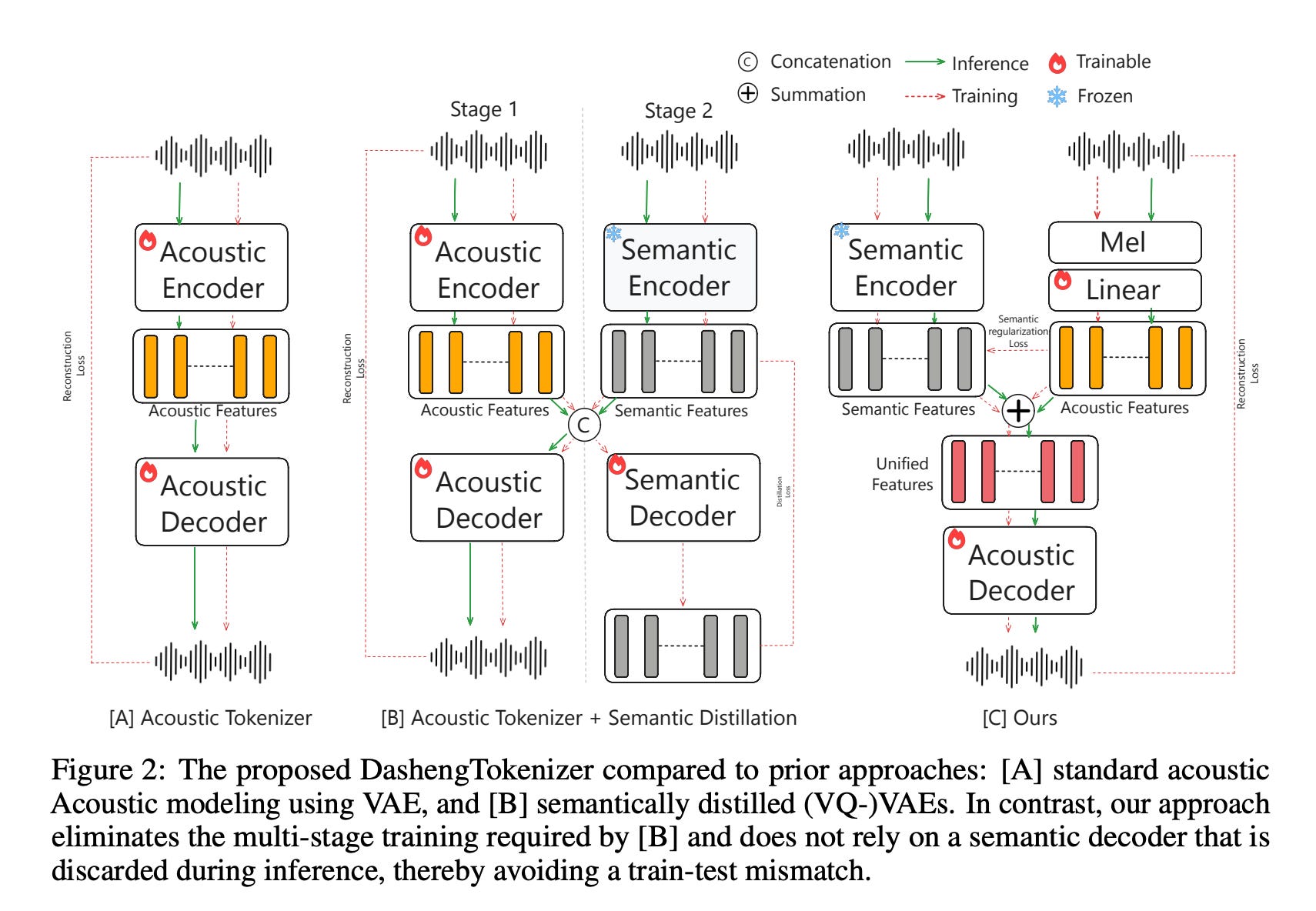
What’s new
A continuous audio tokenizer that handles both understanding and generation by freezing a pretrained semantic encoder and injecting acoustic detail via linear projection. Inverting the usual “acoustic-first” paradigm.
How it works
630M-param frozen semantic encoder provides the backbone representation.
A tiny 0.66M-param acoustic encoder (2D conv on mel-spectrogram) captures speaker/prosody info.
Additive fusion merges both streams; a semantic preservation loss prevents acoustic features from overwhelming the semantic signal.
173M-param Vocos decoder reconstructs waveforms. Single-stage training, no multi-step RVQ.
Results
State-of-the-art on X-ARES benchmark (22 tasks): CREMA-D 80.56, ESC-50 96.40, MAESTRO 57.65.
Competitive reconstruction quality at 25 Hz token rate.
Outperforms VAE-based tokenizers on text-to-audio generation (FAD 2.22 vs. AudioLDM2’s 3.13).
Why it matters
Shows you can get a unified audio representation by adding a simple acoustic residual to frozen semantics. No need for complex multi-codebook quantization.
📚 Doc-to-LoRA: Learning to Instantly Internalize Contexts
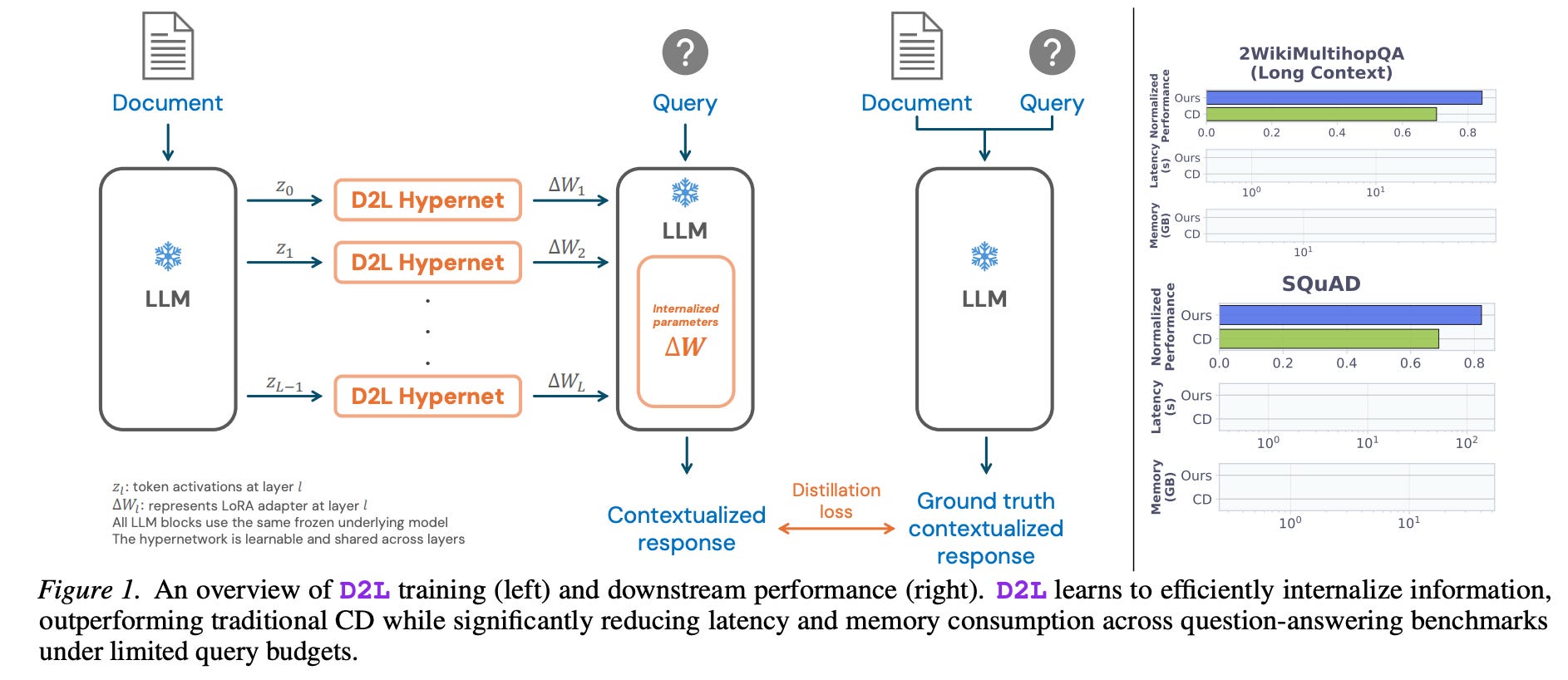
What’s new
A lightweight hypernetwork that meta-learns approximate context distillation in a single forward pass, generating LoRA adapters on-the-fly for a target LLM instead of running expensive per-document fine-tuning.
How it works
A small hypernetwork maps an input document directly to a set of LoRA weight deltas for the target LLM.
At inference the hypernetwork runs once, producing adapter parameters that “internalize” the document into the LLM’s weights. No iterative gradient updates needed.
Approximates full context distillation but collapses the multi-step optimization into a single forward pass, drastically cutting latency and memory.
Results
On needle-in-a-haystack retrieval tasks, D2L achieves near-perfect zero-shot accuracy at context lengths 4× beyond the LLM’s native window.
On real-world long-document QA benchmarks it outperforms standard context distillation while using significantly less peak memory and update time.
Why it matters
Removes the main bottleneck of context distillation, the per-document fine-tuning loop, making it practical for on-the-fly deployment. Enables effective use of very long contexts without extending the base model’s context window, useful for retrieval-augmented and document-grounded applications.
🎵 FlexiCodec: A Dynamic Neural Audio Codec for Low Frame Rates
What’s new
A dynamic-frame-rate neural audio codec that adaptively merges semantically similar frames, letting a single model operate anywhere from 3 Hz to 12.5 Hz instead of the fixed 50 Hz typical of current codecs.
How it works
An ASR-feature-assisted dual-stream encoder processes the audio: one stream captures semantic content, the other acoustic detail.
A transformer bottleneck learns to merge consecutive frames whose ASR features are similar, producing a variable-length discrete token sequence.
The merge ratio is controllable at inference, so users can trade off frame rate against reconstruction fidelity depending on the downstream task.
A matching decoder reconstructs waveforms from the variable-rate token stream.
Results
At 6.25 Hz: 4.15% WER on speech intelligibility vs. 31.5% WER for DualCodec baseline at the same rate.
Delivers competitive TTS quality at substantially lower token rates, translating to significant autoregressive-decoding speedups.
Maintains high audio fidelity across the full 3–12.5 Hz operating range.
Why it matters
Dramatically reduces the sequence length LLM-based TTS systems must generate, directly cutting inference cost and latency. A single controllable codec replaces multiple fixed-rate models, simplifying the speech-generation pipeline. The ASR-guided merging principle could generalize to other modalities where redundant frames dominate.
🗣️ MSR-Codec: Low-Bitrate Multi-Stream Residual Codec for High-Fidelity Speech Generation
What’s new
A low-bitrate multi-stream residual codec that factorizes speech into four explicit streams; semantic, timbre, prosody, and residual. Achieves implicit disentanglement without adversarial losses (unlike NaturalSpeech 3), relying instead on progressive residual fusion.
How it works
Timbre: frozen CAM++ speaker encoder → single L2-normalized utterance-level embedding.
Semantic: frozen HuBERT → 25 Hz features quantized into discrete tokens (500-center codebook).
Prosody: Enc1 + Enc2 downsample mel-spec to 12.5 Hz; residual between Enc2 output and Dec1 (timbre+semantic) output is quantized via VQ1; explicit F0/energy prediction loss supervises the prosody codebook.
Residual: 25 Hz Enc1 output minus upsampled prosody-enhanced stream, quantized via VQ2 for fine-grained acoustic detail.
Streams progressively fused through residual connections across Dec1→Dec2→Dec3; pre-trained Fre-GAN vocoder converts final mel-spec to waveform.
Two-stage AR TTS model: Stage 1 Semantic Decoder (18-layer transformer) predicts semantic tokens at 12.5 Hz; Stage 2 Acoustic Decoder (3-layer transformer) predicts prosody + residual tokens per frame.
Results
200×+ compression (62.5 tokens/s) at 424–612 bps with highest speaker similarity (0.80–0.83) among compared codecs.
TTS (0.2B params, 45k hrs data): SOTA WER on Seed-TTS-eval, highest speaker similarity, and lowest RTF (0.67) , beating FireRedTTS (0.4B/150k hrs), CosyVoice2 (0.5B/167k hrs), and Llasa-1B.
Voice conversion validates disentanglement: timbre swap preserves source prosody (low ΔF0,src); prosody transfer shifts F0 toward target while maintaining source timbre.
Why it matters
Shows that a simple cascaded residual architecture can achieve strong disentanglement without complex adversarial training. Extremely lightweight and data-efficient TTS system that outperforms much larger models in accuracy and speed.
🔍 Multi-Vector Index Compression in Any Modality
What’s new
Attention-Guided Clustering (AGC) for compressing multi-vector document indices in any modality; text, visual documents, and video. Shows that full multimodal indices are massively over-provisioned (base models use only ~1% of tokens during retrieval).
How it works
Learned “universal query” tokens attend over all document tokens to compute per-token saliency scores.
Top-k salient tokens become cluster centroids; remaining tokens hard-assigned to nearest centroid by cosine similarity.
Weighted aggregation pools each cluster using saliency as importance weights — keeps gradients flowing through hard assignments.
Compared against SeqResize (MLP projection along sequence dim), MemTok (learnable appended tokens), and H-Pool (agglomerative merging).
Results
AGC consistently outperforms other learned compression (SeqResize, MemTok).
More flexible than H-Pool (can target specific budgets cleanly).
Competitive with, and sometimes better than uncompressed indices on ViDoRe and MSR-VTT (compression acts like denoising).
Why it matters
Makes ColBERT-style late-interaction retrieval practical for large multimodal collections. ~98% index compression with negligible quality loss. Key insight: multimodal tokens (audio frames, video patches) are far more redundant than text tokens.
🗣️ MeanVoiceFlow: One-Step Nonparallel Voice Conversion with Mean Flows
What’s new
One-step nonparallel voice conversion model based on mean flows — trained from scratch, no teacher model or distillation required. Matches multi-step quality in a single forward pass.
How it works
Replaces instantaneous velocity (standard flow matching) with average velocity, which computes the exact time integral between two points in one step. No ODE solver discretization error.
A structural margin reconstruction loss (SSIM-based + margin threshold) acts as a zero-input constraint to stabilize learning without causing over-smoothed outputs.
Conditional diffused-input training: mixes noise and source mel-spectrogram during both training and inference, maintaining consistency and letting the model leverage source speaker info.
Results
Matches multi-step flow-matching and distillation-based VC models on speech quality and speaker similarity.
Outperforms other from-scratch one-step approaches.
Single-step inference, no iterative sampling.
Why it matters
Removes the pretraining → distillation pipeline from one-step VC: simpler training, same quality. Mean flows are an underexplored alternative to consistency models and shortcut models for single-step generation.
⚙️ PISA: Preconditioned Inexact Stochastic ADMM for Deep Models
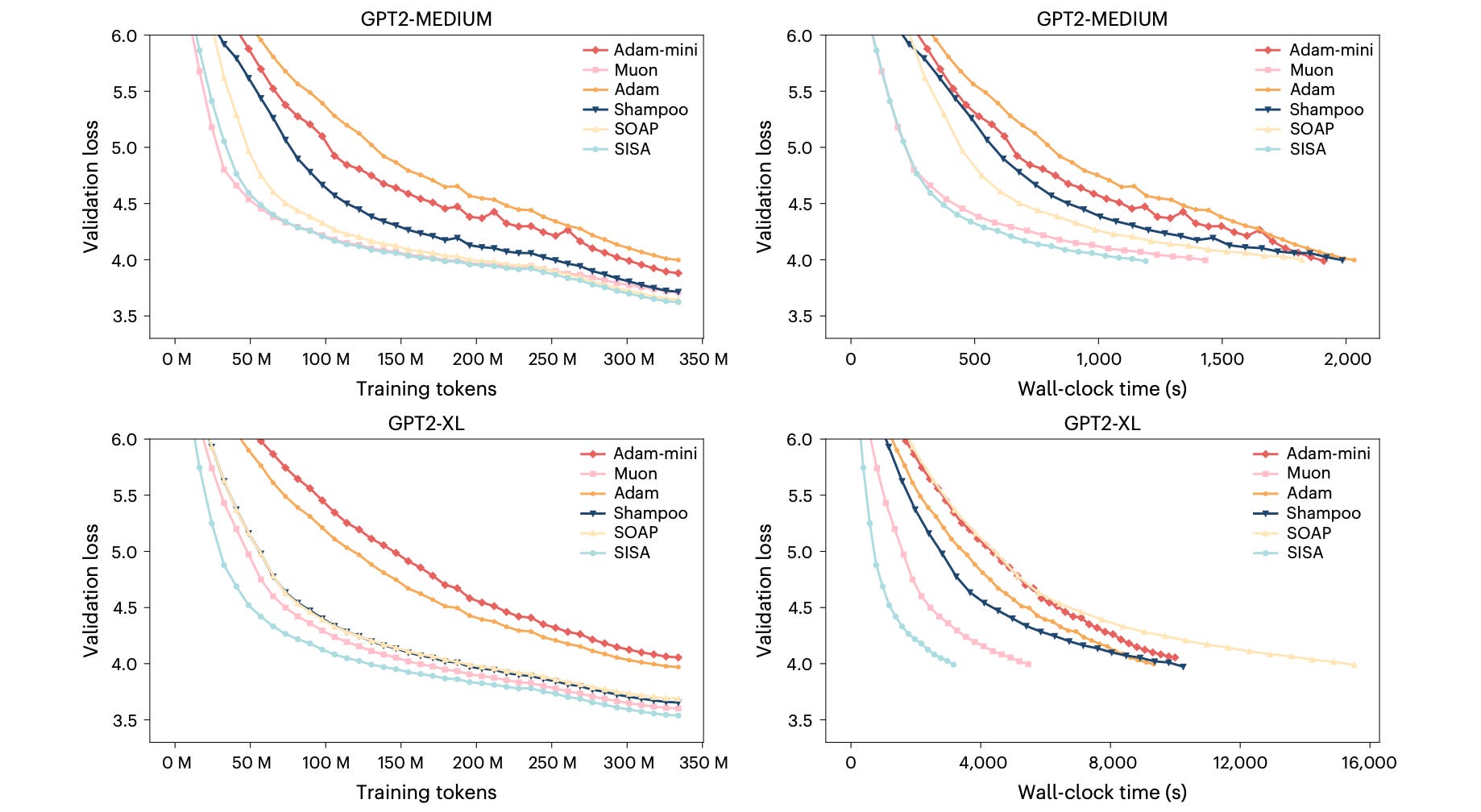
What’s new
A new optimizer family that replaces SGD-based training with an ADMM-based framework. Two efficient variants: SISA (second-moment-based) and NSISA (Newton-Schulz orthogonalized momentum).
How it works
Reformulates training as a constrained optimization problem, splitting data across m batches with auxiliary variables and Lagrange multipliers.
Solves subproblems inexactly using stochastic gradients with adaptive preconditioning matrices (second-moment like Adam, Hessian, or Newton-Schulz orthogonalization like Muon).
Global parameter aggregation step followed by parallel local updates, naturally supports federated/distributed settings.
Convergence proven under only Lipschitz continuity of the gradient on a bounded region. No bounded variance, IID, or unbiased gradient assumptions needed.
Results
NSISA outperforms AdamW, Muon, Shampoo, SOAP, and Adam-mini on GPT-2 Nano/Medium/XL.
SISA achieves lowest FID on GAN training (WGAN, WGAN-GP on CIFAR-10).
Competitive or best accuracy on vision models (VGG-11, ResNet-34, DenseNet-121, ImageNet ResNet-18).
🧑💻 Open Source
RightNow-AI/openfang — Open-source Agent Operating System.
rlacombe/distillate — Automates paper reading workflow between Zotero and reMarkable.
D4Vinci/Scrapling — 🕷️ Adaptive web scraping framework handling everything from single requests to full-scale crawls.
koala73/worldmonitor — Real-time global intelligence dashboard with AI-powered news aggregation, geopolitical monitoring, and infrastructure tracking.
Thanks for reading… Enjoyed this issue? Share it with a friend. 👍