
Machine Learns - 66
Attention Residuals rethink skip connections, the LM head as a gradient bottleneck, Fish Audio S2 open-sources competitive TTS, and a heavy papers section on optimizers, calibration, and audio-driven

🤖 Model Releases
🌐 Phi-4-Reasoning-Vision-15B — 15B open-weight multimodal reasoning model from Microsoft. Phi-4-Reasoning backbone + SigLIP-2 vision encoder, mid-fusion architecture. Outperforms much larger models on reasoning benchmarks.
try:
keep_learning()
except NotSubscribed:
newsletter.subscribe()🗣️ Fish Audio S2 — Open-sourced TTS with multi-speaker, multi-turn generation and instruction-following via natural language. Dual-AR model, RL-aligned post-training, SGLang inference engine (RTF 0.195, TTFA 100 ms). 81.88% win rate on Emergent TTS Eval. Weights + fine-tuning code released.
👂 Granite 4.0 1B Speech — 1B speech-language model from IBM for multilingual ASR + bidirectional speech translation. 6 languages, keyword biasing, speculative decoding via CTC drafts. Average WER 5.52 on HF Open ASR Leaderboard at 280× real-time — competitive with 8B models at half the size.
🧠 NVIDIA Nemotron v3 — 120B total / 12B active MoE hybrid (Mamba-2 + Attention + MTP), 1M context, 7 languages. NVFP4 precision. Beats GPT-OSS-120B on agentic (SWE-bench 60.5% vs 41.9%), reasoning (HMMT Feb25 94.7%), and long-context (RULER@1M 91.8% vs 22.3%). Also ships as Nano-30B (3B active) and Nano-4B. Open weights + data + recipes.
⚡ RedHatAI Speculator Models — EAGLE-3 draft models for speculative decoding of Llama-3/4, Qwen3, and GPT-OSS. 1.5–2.5× latency reduction (up to 4.9× on Llama-4-Maverick math @ 8×B200) with zero quality loss. ~15 model-specific speculators, plug-and-play with vLLM.
🧠 Qwen3.5-27B-Claude-Opus-Reasoning-Distilled — 27B community distillation of Claude 4.6 Opus reasoning traces into Qwen3.5 via LoRA + Unsloth. Replaces repetitive <think> loops with structured CoT. Native “developer” role support for coding agents. ~30 tok/s on RTX 3090 (Q4_K_M, 16.5 GB VRAM). GGUF format.
📎 Papers
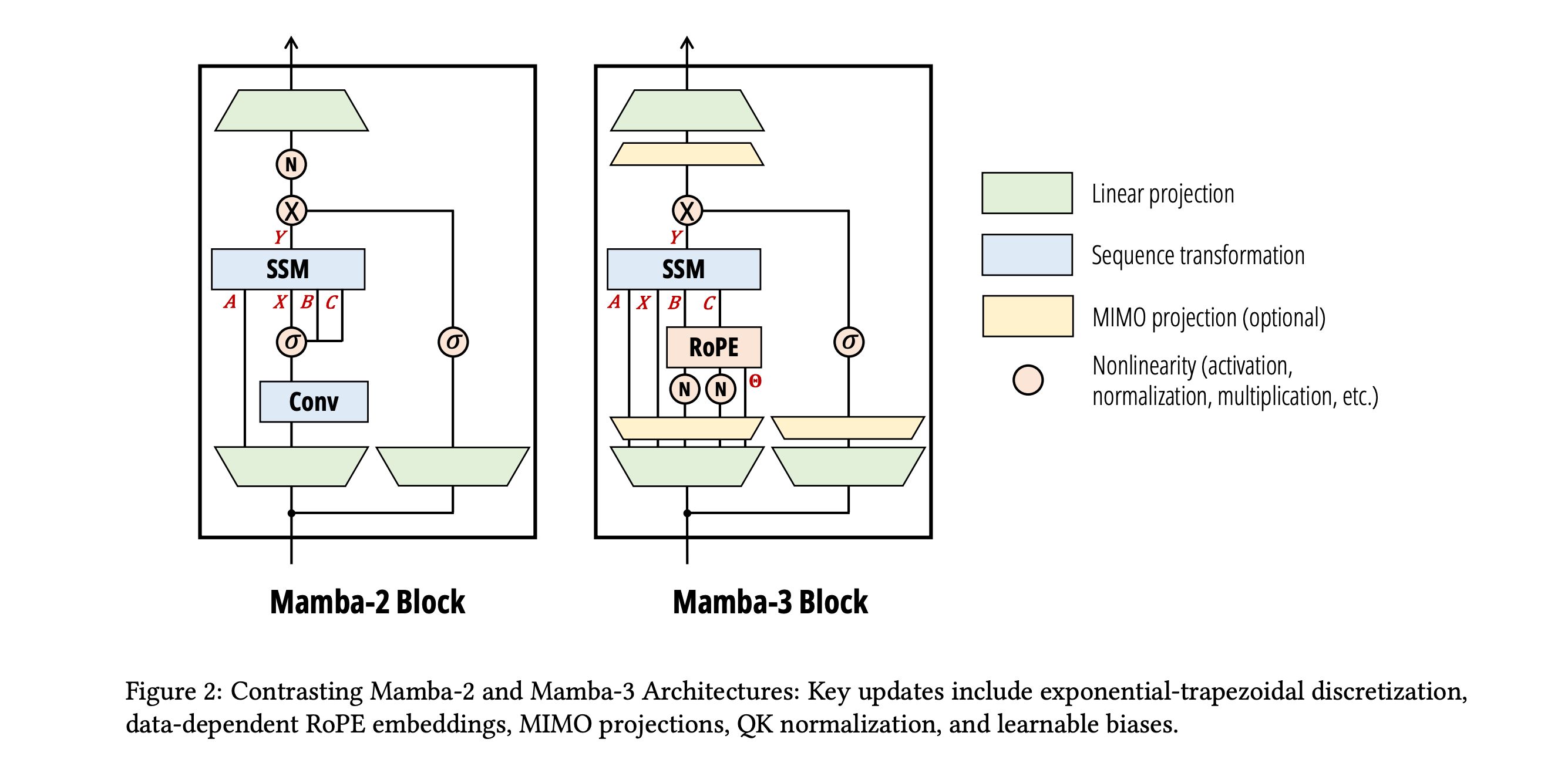
🧠 Mamba-3: Improved Sequence Modeling using State Space Principles
What’s new
Redesigns the core state-space recurrence from first principles — fixes expressiveness, state dynamics, and hardware utilization simultaneously. Removes the short convolution entirely. Matches Mamba-2 quality at half the state size.
How it works
A more accurate way to update the hidden state each step — the old method (Euler) only looks at the current input, while the new one averages current and next inputs, capturing dynamics the old rule missed. This lets both the input and output projection matrices contribute to updates — richer recurrence at no extra cost.
Uses complex numbers in the state, which lets it naturally represent oscillating patterns (think: repeating structures in language) that real-valued states struggle with.
Multi-Input Multi-Output (MIMO): widens the input/output projections by a small factor R, so each step does more useful math per byte of memory read. Since decoding is bottlenecked by memory bandwidth (not compute), the extra arithmetic is essentially free — wall-clock barely changes at R=4.
Hybrid models (5:1 Mamba-3 to attention layers) largely close the retrieval gap vs pure Transformers.
Results
1.5B, 100B tokens: Mamba-3 MIMO val PPL 10.24 vs Transformer 10.51, Mamba-2 10.47. Avg accuracy 57.6 (+2.2 over Transformer).
Mamba-3 MIMO at state size 64 matches Mamba-2 at state size 128 — same quality, half the decode latency.
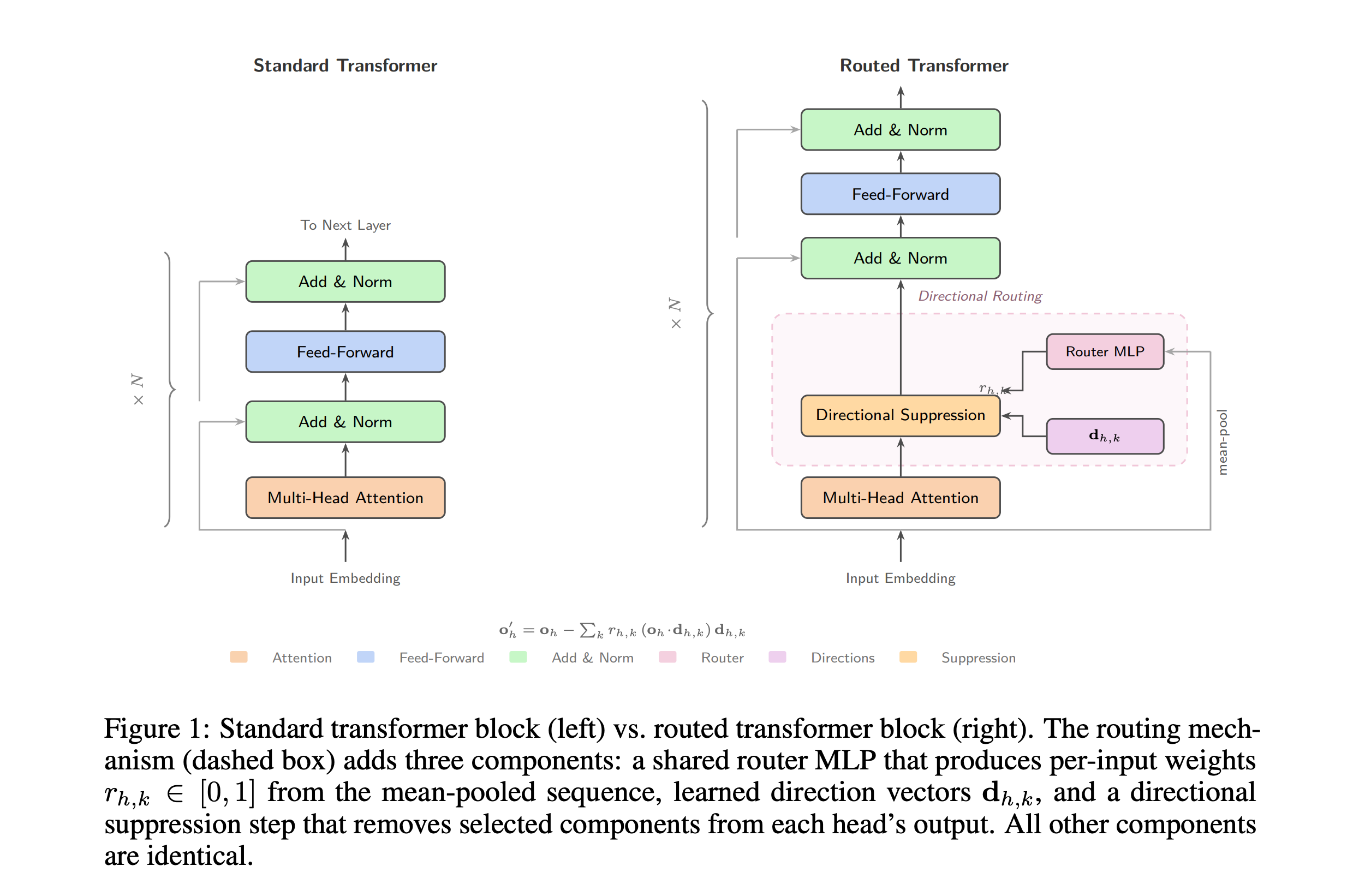
🔬 Directional Routing in Transformers
What’s new
A lightweight mechanism (+3.9% params, +0.02% FLOPs) that gives each attention head 4 learned “directions to suppress,” controlled by a shared MLP router. The router becomes so central to the model that disabling it collapses factual recall to near-zero, while knocking out any individual head has negligible effect.
How it works
Each head learns 4 unit-length direction vectors. A shared 4-layer MLP router outputs per-head gating weights that control how strongly each direction is applied.
After standard attention computes its output, the mechanism projects the output onto each learned direction and subtracts it (scaled by the gating weight) — effectively filtering out interference between different types of information (e.g., preventing factual knowledge from bleeding into syntactic processing).
No auxiliary loss or load-balancing needed. It self-organizes: early layers learn to route by domain/topic, late layers learn to suppress grammar-related features that would otherwise add noise.
Results
433M vs 417M baseline: overall PPL 20.6 vs 42.7 (−51.8%), Math PPL 29.2 vs 66.5 (−56.1%).
The catch: perplexity gains don’t transfer to multiple-choice benchmarks (HellaSwag, ARC) — the routing is better at decoding existing knowledge, not a source of new knowledge. Intriguing mechanistic finding, unclear practical payoff at scale.
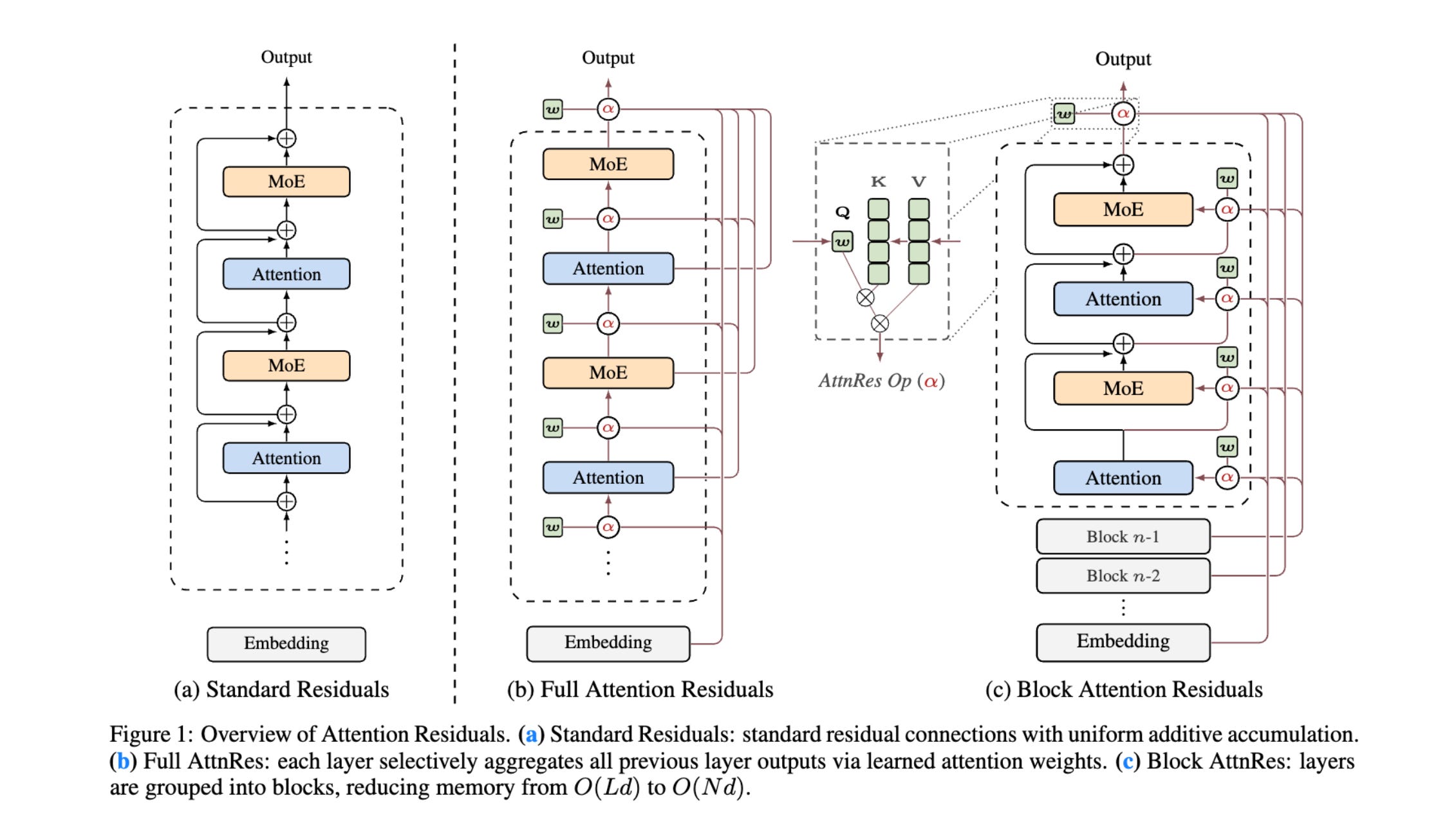
🧠 Attention Residuals (Kimi Team / MoonshotAI)
What’s new
Standard residual (skip) connections just add every layer’s output with equal weight — there’s no way for the network to say “layer 5’s output matters here, but layer 12’s doesn’t.” AttnRes replaces this with learned attention over depth: each layer gets a small learnable query that decides how much weight to give each preceding layer’s output.
Block AttnRes makes it practical: group layers into ~8 blocks and only apply the cross-layer attention at block boundaries, instead of between every single layer. This keeps the memory cost manageable.
How it works
Each layer computes a weighted combination of all prior layer outputs, where the weights come from a softmax attention mechanism — exactly like sequence attention, but operating over layers instead of tokens.
Block variant: normal residual connections within blocks, learned attention only across the ~8 block-level representations. This recovers most of the gains at a fraction of the cost.
All the learnable queries start at zero, so at initialization the system behaves like uniform averaging — this prevents training instability.
Cross-stage caching for pipeline parallelism: <4% wall-clock training overhead.
Two-phase inference keeps overhead under 2%.
Elegant theoretical framing: standard residuals, Highway Networks, and other prior variants are all “linear attention over depth” — AttnRes is “softmax attention over depth.”
Results
Block AttnRes matches the loss of a baseline trained with 1.25× more compute.
Kimi Linear 48B/3B on downstream tasks: GPQA-Diamond +7.5, Math +3.6, HumanEval +3.1, C-Eval +2.9 over baseline.
🔬 Lost in Backpropagation: The LM Head is a Gradient Bottleneck
What’s new
The gradient flowing back from the vocabulary-sized output gets squeezed through a much smaller hidden dimension, crushing most of the useful training signal into noise.
How it works
The gradient signal passing through the LM head has very high rank (nearly vocabulary-sized), but the head can only pass through a tiny fraction of that information — it’s constrained by the hidden dimension, which is orders of magnitude smaller than the vocabulary.
The gap between the ideal gradient update and what actually gets through is mathematically bounded — and it’s large.
SpamLang experiment: a trivially simple synthetic language (just repeat one token) that any Transformer with hidden dim ≥ 2 can perfectly express — yet gradient descent fails to learn it as vocabulary size grows. This cleanly proves the problem is optimization, not model capacity.
Controlled 2B-parameter pretraining (Llama3 backbone) with the LM head forced to a specific rank confirms the effect in real training.
The projected gradient has only 0.1–0.2 cosine similarity with the original gradient — meaning the model sees a heavily distorted version of the true training signal.
Results
95–99% of gradient norm destroyed across GPT-2, Pythia, Llama-3, Qwen3-Base families.
A model with hidden dim 4096 reaches the final loss of a dim-32 model within 700M tokens — a 16× convergence speedup for the same backbone.
SpamLang: vocab size 16384 learns perfectly; vocab size 131072 generates garbage regardless of learning rate.
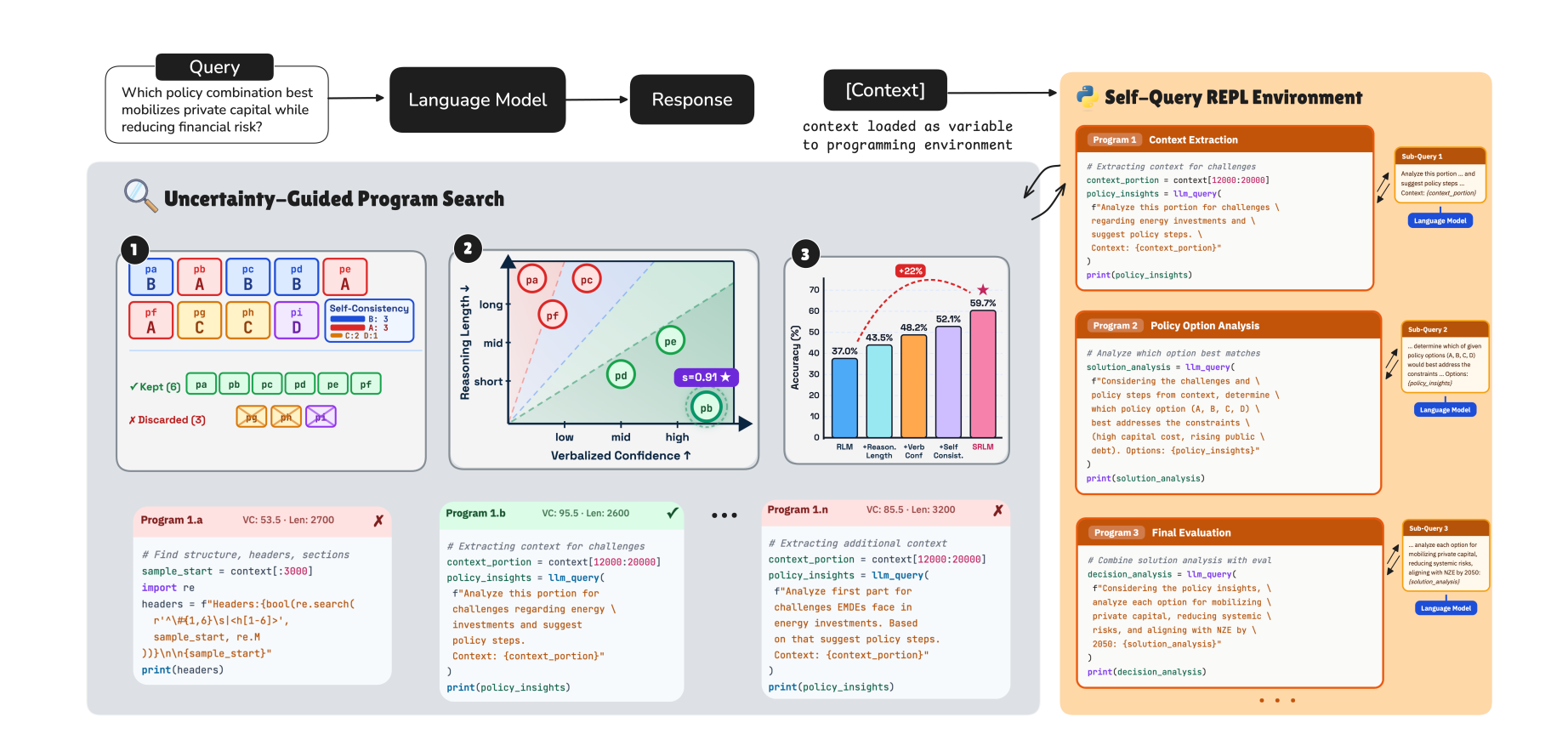
📏 SRLM: Self-Reflective Program Search for Long Context
What’s new
SRLM improves long-context reasoning by combining recursive sub-queries with uncertainty-aware self-reflection. Instead of using fixed heuristics to pick the best reasoning path, it uses the model’s own confidence signals to select the most reliable answer.
How it works
Breaks long contexts into smaller recursive sub-queries executed in a sandboxed programming environment, treating the full context as an external variable the program can reference.
Evaluates candidate reasoning programs using three built-in confidence signals:
Self-consistency: do multiple runs agree on the same answer?
Verbalized confidence: how confident does the model say it is at each step?
Reasoning trace length: how many tokens did it take? (longer deliberation can signal harder sub-problems)
These signals together pick the most reliable reasoning trajectory from the search space.
Results
Qwen3-Coder-480B: LongBench-v2 64.9 (+5.1 over RLM), BrowseComp+ 59.7 (+22.6 over RLM), OOLONG 51.8 (+6.1).
GPT-5: LongBench-v2 68.9 (+9.4), BrowseComp+ 92.4 (+6.4), OOLONG 65.5 (+12.5).
Biggest gain on semantically intensive retrieval: +22.6 absolute on BrowseComp+ with Qwen3.
🗣️ CAST-TTS: Unified Timbre Control via Cross-Attention
What’s new
A unified framework for controlling voice timbre (the quality that makes one voice sound different from another) using cross-attention, accepting both speech clips and text descriptions interchangeably as voice prompts.
How it works
Timbre encoder with two branches: speech prompts go through a speaker encoder; text prompts (like “deep male voice with a warm tone”) go through a Flan-T5 text encoder.
Multi-stage training aligns the speech and text representations into a shared timbre space — so a text description and a matching voice clip land near each other.
Cross-attention in the Transformer backbone lets the model flexibly draw on timbre information from either modality.
Trained with flow-matching loss, optimizing cross-modal feature alignment.
Results
Speech-prompted: SPK-Sim 78.4 (vs F5-TTS 75.4, MaskGCT 74.5), WER 2.05%, UTMOS 3.91.
Text-prompted: Style-ACC 91.15% (vs CapSpeech 88.93%), WER 3.89%, Sim-MOS 4.11.
Best speaker similarity across all baselines while keeping intelligibility competitive.
⚡ Exclusive Self Attention (XSA)
What’s new
Standard self-attention output for a token has high overlap with that token’s own value vector — meaning attention wastes capacity reconstructing per-token features that the residual connection and feed-forward layer already handle. XSA subtracts out the “self-copy” component, forcing attention to focus purely on contextual (cross-token) information. Two lines of code.
How it works
Self-copy bias happens because value vectors within a sequence tend to point in similar directions, and the self-attention score (token attending to itself) is typically high — together causing the output to look a lot like the input.
Side benefit: acts as an implicit attention sink. Attention mass that has nowhere useful to go can safely land on the self-attention score, since the self-copy gets removed anyway.
Results
Downstream accuracy gains: +0.26 (0.7B), +1.03 (1.3B), +1.36 (2.7B) — gains scale with model size and sequence length.
2.7B XSA: ARC-E 60.65, HellaSwag 67.40, LAMBADA 62.04, PIQA 77.80 (vs 58.59, 66.20, 60.18, 76.61 baseline).
⚙️ Mousse: Muon + Curvature-Aware Preconditioning
What’s new
Muon (a recent optimizer) assumes the loss landscape curves equally in all directions — but neural networks have very uneven curvature. Mousse fixes this.
How it works
Mousse measures the curvature along each direction (using a running average of gradient statistics, factored efficiently via Kronecker products) and adjusts step sizes accordingly — take bigger steps in flat directions, smaller steps in steep ones.
Trace normalization: rescales the curvature estimates so their average is 1 across all layers. This is critical because raw curvature magnitudes vary wildly between layers.
Memory ~1.05× Muon, ~0.88× SOAP.
Results
800M model: ~0.012 lower final validation loss than Muon; ~12% fewer steps to converge.
Consistent wins across 160M–800M on FineWeb (20B tokens), on both cosine and WSD LR schedules.
⚡ Flash-KMeans: Fast and Memory-Efficient Exact K-Means
What’s new
GPU k-means: the standard approach materializes a huge distance matrix (every point × every cluster) and uses contention-prone atomic writes. flash-kmeans eliminates both problems while computing exact results (not approximations).
How it works
FlashAssign: streams data in small tiles from main GPU memory to fast on-chip memory, computing distances and finding the nearest cluster on the fly — the full distance matrix is never stored.
This slashes memory traffic from “proportional to points × clusters” down to “proportional to points + clusters.”
Sort-based update: sorts points by their assigned cluster, then does efficient segment-level reductions to compute new centroids.
Handles datasets too large for GPU memory via chunked streaming; an auto-tuning heuristic matches exhaustive tuning within 0.3%.
Results
End-to-end: 17.9× over fast_pytorch_kmeans, 33× over cuML, 200×+ over FAISS on H200.
1 billion points (N=10⁹, K=32768, D=128): 41.4s vs 261.8s baseline.
Handles out-of-memory cases where PyTorch baselines crash (N=1M, K=64K, D=512).
🗣️ TADA: Text-Acoustic Dual Alignment for Speech Modeling
What’s new
Achieves 1-to-1 alignment between text tokens and audio frames using forced alignment — this collapses the usual 10× sequence length gap between text and speech. A 2048-token context covers ~682 seconds of audio.
How it works
A forced aligner (Wav2Vec2-Large backbone) maps each text token to its exact corresponding audio frame using Viterbi alignment.
VAE Encoder compresses 24kHz audio down to 50 frames/sec, then a 6-layer Transformer refines these. A binary flag marks which frames correspond to text token boundaries.
LLM Backbone (Llama 3.2 1B/3B): fuses text and acoustic embeddings by simply adding them together. Uses flow matching with a special binary encoding for duration prediction.
Speech-Free Guidance: blends text-only and text+speech predictions at inference. At weight 0.5, recovers near-text-only language accuracy with only +0.01 RTF overhead.
Trained on 270k hours English + 635k hours multilingual (7 languages).
Results
RTF 0.09 (TADA-1B) — 2–8× faster than all baselines.
SeedTTS-Eval: CER 0.73, SIM 77.9. Zero hallucinations.
Text perplexity 19.6 on Seamless Interaction as spoken LM (beats Llama-3B-Instruct’s 20.9 while 2× smaller).
📚 Believe Your Model: Distribution-Guided Confidence Calibration
What’s new
DistriVoting: a test-time scaling method that samples multiple reasoning paths, then uses the distribution of confidence scores to separate likely-correct from likely-incorrect answers.
How it works
Trajectory Confidence: measures how concentrated the model’s probability is on its chosen answer (using the negative log-probability over top-k predictions at the answer step).
SSC: tracks a running average of step-level confidence. When confidence drops sharply below the running threshold, it intervenes and forces the model to output a reflection/reconsideration token.
GMM Filter: fits a 2-component Gaussian mixture to the confidence scores across N sampled trajectories. The higher-confidence component is presumed correct.
Reject Filter: from the lower-confidence component, identifies the most likely wrong answer and removes all matching trajectories from the final pool.
Results
DeepSeek-R1-8B (5-benchmark avg): Self-Consistency 73.09% → DistriVoting+SSC 77.84% (+4.75pp).
HMMT2025: 69.11% → 84.95% (+15.84pp).
Qwen3-32B: 73.85% → 76.61% (+2.76pp).
GMM: 60.46% trajectory correctness prediction, 1.78× faster than K-Means.
⚙️ SUMO: Subspace-Aware Moment-Orthogonalization (NeurIPS 2025)
What’s new
Muon-style optimizers approximate the matrix square root using an iterative method (Newton-Schulz) that introduces error — especially when the gradient has uneven singular values, which is common during LLM training. SUMO replaces this approximation with an exact decomposition computed in a smaller, dynamically chosen subspace. Faster convergence with up to 20% less memory.
How it works
Computes exact SVD (singular value decomposition — the precise way to find the principal directions of the gradient) within a low-dimensional subspace that adapts as the gradient’s effective rank changes during training.
Takes optimization steps aligned with the actual curvature of the loss surface, rather than an approximation of it.
Shows theoretically that the Newton-Schulz approximation error grows with the condition number (how spread out the gradient’s singular values are) — and this is typically high during LLM training.
Results
Faster convergence than GaLore, Flora, and Muon on fine-tuning benchmarks.
Up to 20% memory reduction vs comparable low-rank methods.
Evaluated on 350M–1B+ models (Phi-2, LLaMA).
🧑💻 Open Source
Nutlope/open-deep-research — Open Deep Research app for generating reports with OSS LLMs.
Martian-Engineering/lossless-claw — Lossless Context Management plugin for OpenClaw.
FireRedTeam/FireRedVAD — Industrial-grade VAD and audio event detection, 100+ languages, outperforms Silero-VAD, TEN-VAD, FunASR-VAD, and WebRTC-VAD.
obra/superpowers — Agentic skills framework for coding agents. Composable specification → plan → subagent-driven development with TDD, YAGNI, DRY built in.
googleworkspace/cli — Google Workspace CLI for Drive, Gmail, Calendar, Sheets, Docs, Chat, Admin. Built from Discovery Service; includes AI agent skills.
rtk-ai/rtk — CLI proxy that reduces LLM token consumption by 60–90% on dev commands. Single Rust binary, zero dependencies.
Thanks for reading… Enjoyed this issue? Share it with a friend. 👍