
Machine Learns - 67
This week: Mistral ships open TTS that beats ElevenLabs, Mamba-3 recovers state tracking, and a 1-bit 8B model that fits in 1 GB.

🧑💻 My new open-source projects
I little self-promotion
⭐️ TokLog - Local LLM cost proxy. pip install toklog && tl proxy start - zero code changes, per-call breakdowns, and a kill switch for runaway agent loops. No cloud, no account.
⭐️ ngi - Trigram-indexed regex search in Rust. 2-6x faster than ripgrep on repeated queries. ngi index once, search instantly forever.
🤖 Model Releases
🗣️ Voxtral-4B-TTS-2603 - Mistral’s first open TTS. Zero-shot voice cloning from 3s of audio, 9 languages, beats ElevenLabs in 68.4% of human evals. vLLM-compatible. CC BY-NC 4.0.
try:
keep_learning()
except NotSubscribed:
newsletter.subscribe()🗣️ LongCat-AudioDiT-3.5B - Meituan’s TTS that ditches mel-spectrograms for raw waveform latent space. 3.5B Diffusion Transformer, beats prior SOTA on zero-shot voice cloning (0.818 vs 0.809 speaker similarity). MIT.
🎭 daVinci-MagiHuman - 15B model generating synced video + audio from a reference image and text. 80% win rate vs Ovi 1.1, 5s 1080p clip in 38s on H100. Multilingual (CN/EN/JP/KR/DE/FR). Fully open-source.
🌐 Harrier-OSS-v1-27B - Microsoft’s multilingual embedding model. SOTA on Multilingual MTEB v2, 32K context window, 100+ languages. Ships in 270M, 0.6B, and 27B sizes.
🌐 Bonsai-8B - End-to-end 1-bit LLM (Qwen3-8B) that fits in 1.15 GB. Not a quantization - purpose-built 1-bit. 70.5 avg on 6 benchmarks, 6.2x faster than FP16 on RTX 4090. Apache 2.0.
🖼️ SAM 3.1 - Meta’s Segment Anything update. New Object Multiplex makes multi-object tracking 7x faster at 128 objects with no accuracy loss. Better VOS on 6/7 benchmarks. Apache 2.0.
👂 Cohere Transcribe - Cohere’s first open ASR. 2B params, 14 languages, long-form with auto-chunking. 58k+ downloads in week one. Apache 2.0.
🌐 pplx-embed - Perplexity’s embedding family with a diffusion-pretrained backbone. pplx-embed-v1 competitive on Multilingual MTEB v2; pplx-embed-context-v1 SOTA on ConTEB. 0.6B and 4B sizes, 1M+ downloads.
🧠 Nemotron-Cascade 2 - NVIDIA’s open 30B MoE with only 3B active params. Gold Medal at 2025 IMO, IOI, and ICPC - second open-weight model ever to hit that bar. Weights, data, and full training recipe open-sourced.
📎 Papers
⚡ Aurora: When RL Meets Adaptive Speculative Training
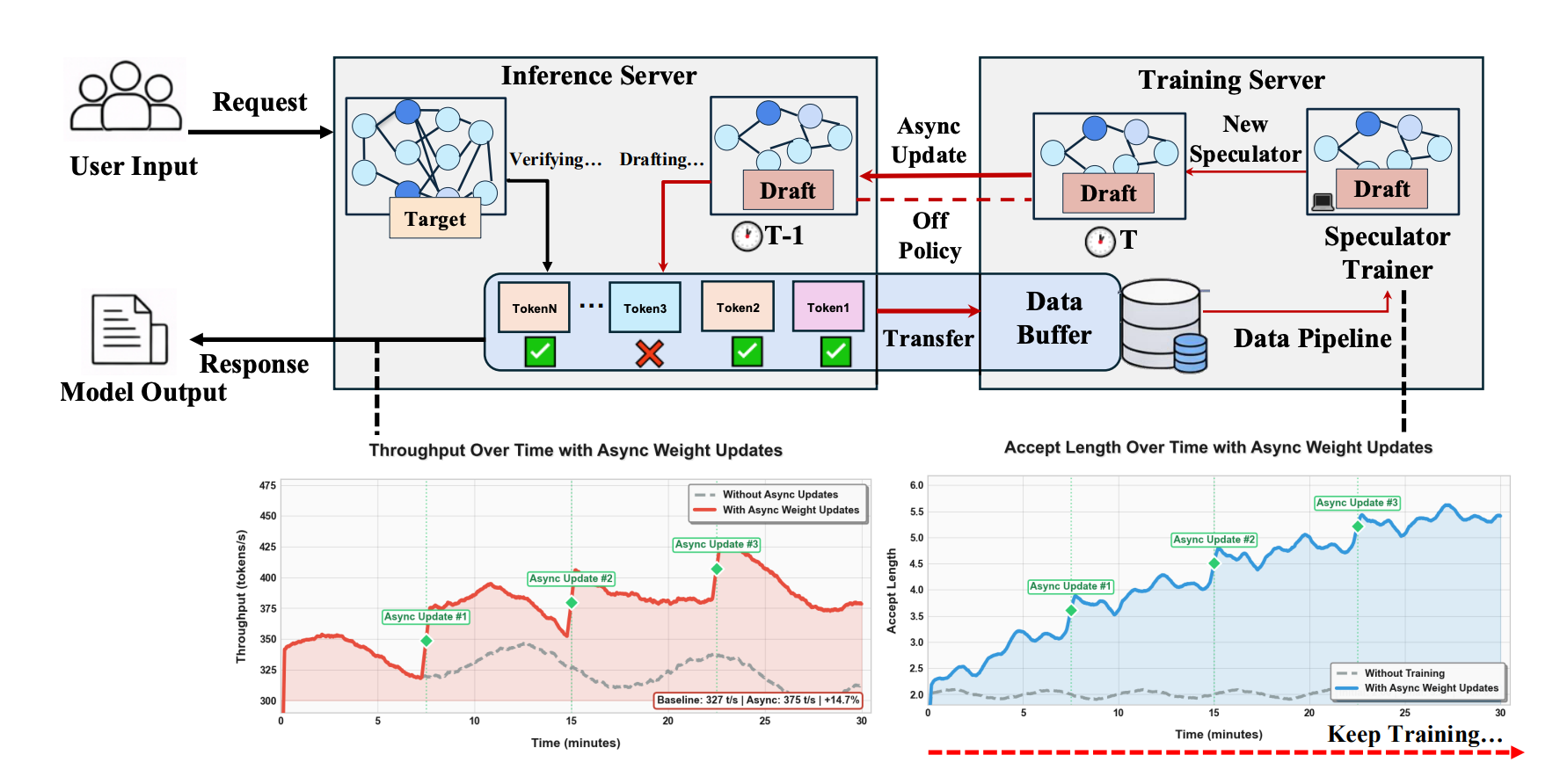
What’s new
• Speculative decoding usually means: train a small “draft” model offline to predict tokens, then use it to speed up a large model at inference. Aurora closes the loop - the draft model learns continuously from live inference traffic instead of being trained once and frozen.
• Day-0 deployment: serve a brand-new model with an untrained speculator immediately; it improves itself in real time.
How it works
• Reframes speculative decoding as asynchronous RL: the draft model is the policy, accepted/rejected tokens are the reward signal.
• Learns from both accepted tokens (imitation) and rejected tokens (counterfactual - “stop proposing this”), giving much denser training signal.
• New speculator weights hot-swapped into the live inference server without downtime via lazy synchronization.
Results
• 1.5× day-0 speedup on frontier models (MiniMax M2.1 229B, Qwen3-Coder-Next 80B) with a cold-start speculator.
• 1.25× additional speedup over a well-trained static speculator by adapting to real user traffic distribution.
Why it matters
• Eliminates “train a drafter offline for weeks before deployment.” Speculators no longer go stale when the target model or user patterns change.
🗣️ MOSS-VoiceGenerator: Create Realistic Voices with Natural Language Descriptions
What’s new
• You can describe a voice in plain English - “deep, gravelly, slightly warm, like a late-night radio host” - and generate it. No reference audio needed.
• Most TTS customization requires a sample clip. This eliminates that entirely.
How it works
• A language model generates audio tokens from text descriptions the same way it generates word tokens from a prompt.
• Trained on ~5,000h of cinematic speech (movies, TV) annotated with timbre descriptions - richer and more varied than studio recordings, which sound sterile.
• Retrieval mode: can also search a voice database to find the closest match to your description and clone from there.
Results
• Beats prior methods on naturalness, instruction-following, and overall quality in human preference studies.
🧠 Hyperagents: Metacognitive Self-Modification
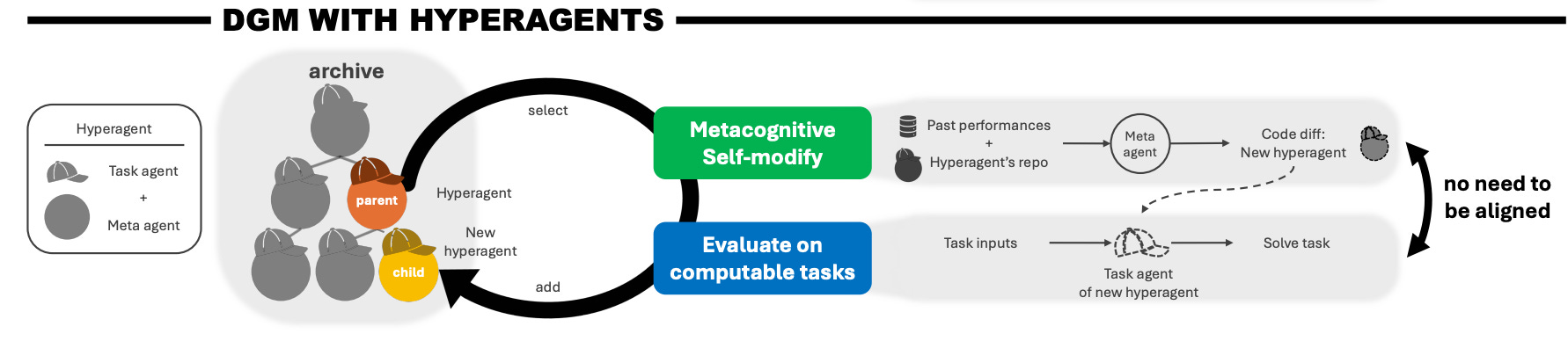
What’s new
• An AI agent that rewrites its own instructions, tools, and evaluation criteria - then applies those changes to future runs. Not just self-reflection: actual self-modification that persists.
• Prior self-improving agents only worked in coding. This one generalizes across math, reasoning, and general tasks.
How it works
• Two-layer loop: a task agent does the work; a meta-agent watches, judges, and edits both the task agent’s prompts/tools and its own judgment criteria.
• Nothing is frozen - the meta-agent can rewrite its own evaluation logic if it decides it was grading wrong.
• Improvements compound - each generation of modifications builds on the last, like iterative refactoring but for agent behavior.
Results
• Outperforms strong self-improving agent baselines on coding, math, and general reasoning.
• Performance gains compound across iterations - later runs significantly outperform earlier ones.
⚡ TurboQuant: Redefining AI Efficiency with Extreme Compression
What’s new
• Google’s two-stage compression algorithm combining PolarQuant (high-quality compression) and QJL (Quantized Johnson-Lindenstrauss - a 1-bit error correction layer on top).
How it works
• PolarQuant: randomly rotate data vectors to simplify geometry, then compress. Think of it as: before compressing, rearrange the data so it’s easier to compress accurately.
• QJL: uses just 1 bit to detect errors from the first stage while preserving the relative distances between vectors - so you can still find “similar” vectors correctly.
• Two stages: compress aggressively first, catch the errors second. The combination gives extreme compression with minimal quality loss.
Results
• Reduces key-value cache memory by at least 6x without accuracy loss.
• Up to 8x speedup in computing attention scores on H100 GPUs.
• Gemma 2 2B retains benchmark performance under TurboQuant compression.
Why it matters
• Practical path to running large models on memory-constrained hardware. The attention cache is often the memory bottleneck - 6x smaller cache means much longer context windows on the same hardware.
🧠 Mamba-3: Improved Sequence Modeling using State Space Principles
What’s new
• Mamba-2 was fast but broke on tasks requiring memory - like tracking whether a running count is odd or even across thousands of tokens. It performed at random chance. Mamba-3 fixes this while getting more efficient.
How it works
• The hidden state now stores complex numbers instead of real ones. Complex numbers can represent rotation, which gives the model a built-in sense of position and periodicity - the thing it was missing for counting and tracking.
• More efficient state updates: the recurrence now uses matrix multiplication instead of a less expressive outer-product operation, packing more information into the same memory footprint.
• Since decoding is bottlenecked by memory bandwidth (not compute), the extra matrix math costs almost no wall-clock time.
Results
• Near-perfect state-tracking accuracy where Mamba-2 performs at chance.
• Matches Mamba-2 quality with half the memory - same output, half the RAM.
• +1.8 accuracy points over the best alternative at 1.5B scale.
Why it matters
• State tracking is a prerequisite for any agent that needs to follow multi-step instructions reliably. This closes the gap that made linear models a risky bet for production. Already being adopted in Qwen3 and Nemotron hybrids.
🧠 M²RNN: Non-Linear RNNs with Matrix-Valued States
What’s new
• An RNN where the hidden state is a matrix instead of a vector, with non-linear transitions. The key insight: non-linear RNNs weren’t abandoned because non-linearity is bad - they were abandoned because their state was too small. Matrix-valued states fix this.
How it works
• Each recurrent layer maintains a matrix-shaped hidden state with expressive non-linear updates. Matrix structure naturally exploits GPU tensor cores.
• Hybrid design: most layers are attention, some swapped for M²RNN recurrent layers. Even replacing a single attention layer yields meaningful gains.
Results
• Beats Gated DeltaNet hybrids by 0.4–0.5 perplexity points on a 7B mixture-of-experts model using 3× smaller recurrent state.
• Perfect state tracking that generalizes to sequence lengths unseen during training.
• +8 points on LongBench over SOTA hybrid linear attention architectures.
Why it matters
• Transformers are provably unable to do certain tasks natively (like entity tracking across many steps). M²RNN layers can - and they’re cheap to add. A compelling plug-in upgrade rather than a full replacement.
🧠 λ-RLM: The Y-Combinator for LLMs
What’s new
• LLMs can already write code to break down long documents - but that code crashes, loops forever, or hallucinates. λ-RLM replaces free-form code generation with a small fixed vocabulary of safe operations (Split, Filter, Map, Reduce).
• Think of it as giving the model Lego bricks instead of raw clay: the pieces are constrained, but you can build anything.
How it works
• The LLM picks operations from the library to decompose a task into small enough pieces to fit in its context window. Actual execution is deterministic - no surprises.
• Recursion is handled via the Y-combinator (a computer science primitive), which guarantees termination and makes execution cost predictable before it starts.
Results
• Wins 29/36 model-task comparisons vs. standard recursive LLMs across 9 models and 4 benchmarks.
• Up to +21.9 accuracy points and 4.1× faster.
Why it matters
• The agent does the thinking; the runtime does the orchestration. You get better accuracy, formal correctness guarantees, and predictable cost - instead of hoping the LLM writes valid code.
🗣️ Any2Speech: Borderless Long Audio Synthesis
What’s new
• Standard TTS reads one sentence at a time with no memory of what came before. Any2Speech adds scene awareness: it knows who’s speaking, what the emotional arc is, and how the current line fits into the whole scene.
• Most TTS datasets are built by filtering noisy audio. This one keeps everything and annotates it instead - capturing natural breath, emotion, and multi-speaker dynamics that filtered datasets lose.
How it works
• The model gets three layers of context: scene level (who are these people, what’s the mood), sentence level (what’s the intent of this line), word level (how to stress and pronounce it).
• Before synthesizing, the model writes a plan - tone, pacing, emotion per sentence - using chain-of-thought reasoning. You can edit the plan before generating audio.
Results
• Demo-based evaluation only (no standard benchmark covers long-form scene-aware synthesis yet).
• Uses >90% of training data vs. the typical 10-30% retained after aggressive quality filtering.
Why it matters
• Closes the gap between TTS and actual voice acting. The model can direct its own delivery from a script rather than blindly reading words.
🤔 Agentic Confidence Calibration
What’s new
• When should an AI agent trust its own answer? This paper builds a confidence calibration system that watches how the agent reasoned - not just what it concluded.
• Most calibration methods look at the output. This one looks at the journey: did confidence fluctuate? Did it spike or crash at unusual steps?
How it works
• Records a confidence trace across every step of the agent’s execution - how certain it was at each point.
• Extracts features from that trace: how much confidence changed between steps, how volatile it was within a step, which early or late steps best predicted success.
• Maps those features to a calibrated confidence score using a lightweight model.
Results
• Outperforms strong baselines across 8 benchmarks on calibration quality.
• Generalizes across different agent architectures.
Why it matters
• An agent that confidently gives a wrong answer is more dangerous than one that says “I’m not sure.” Process-level signals catch uncertainty that output-only methods miss entirely.
⚡ Data-Efficient Pre-Training by Scaling Synthetic Megadocs
What’s new
• When you’re running out of unique training data (increasingly everyone), generating rephrases of your documents and mixing them in actually improves performance on the original distribution.
• The key trick: stitch rephrases into one long “megadoc” per source document instead of treating each as a separate training example.
How it works
• Simple rephrasing: generate multiple rephrasings per document, mix into training. Improves monotonically, plateauing at ~1.48× data efficiency at 32 rephrases.
• Megadocs: concatenate all rephrases into one long document (or insert generated rationales inline to “stretch” the original).
• Allows 5× more training steps without overfitting - epoch real data 32 times instead of 16.
Results
• Megadocs push data efficiency from 1.48× to 1.80× at 32 generations per document.
• Improvements on loss, downstream benchmarks, and especially long-context loss (0.14–0.19 improvement).
Why it matters
• A concrete recipe for hitting the data wall. By organizing synthetic variants into longer coherent documents, you resist overfitting much longer. Very relevant as unique web text becomes scarcer.
🧠 Thinking in Uncertainty: Mitigating Hallucinations with Latent Entropy-Aware Decoding
What’s new
• LEAD (Latent Entropy-Aware Decoding): a decoding strategy for multimodal reasoning models that switches between two modes based on how uncertain the model is token-by-token.
How it works
• High-entropy (uncertain) states: instead of picking a token, the model uses a probability-weighted blend of possible token embeddings - staying in “soft” space, preserving semantic diversity.
• Low-entropy (confident) states: revert to discrete token selection for precise convergence.
• Visual anchor injection: during high-entropy phases, reintroduce visual features to keep the model grounded in the image.
• Persistence window: prevents rapid oscillation between modes (once you switch, you stay for a few steps).
Results
• +4.7% improvement on hallucination benchmarks averaged across models.
• +2.0% on mathematical reasoning tasks.
🔬 Scaling Reward Modeling Without Human Supervision
What’s new
• Reward models - the systems that teach AI what “good” looks like during training - normally require thousands of human preference labels. This paper trains them on raw web text instead.
• The key insight: a document’s natural continuation is probably better than a random mismatch. That’s all you need to build a preference signal at scale.
How it works
• Take any web document. The second half is the “preferred” completion; a random snippet from elsewhere is the “rejected” one. Train the reward model to distinguish between them.
• Same training objective as human-labeled RLHF - just with implicit labels scraped from the web at zero cost.
• Demonstrated on 11M tokens of math-focused text.
Results
• +7.7 points average on RewardBench v2 (a standard reward model quality benchmark).
• +16.1 points on math-specific subsets.
• Downstream math performance improves significantly when used for model fine-tuning.
🧠 Directional Routing in Transformers
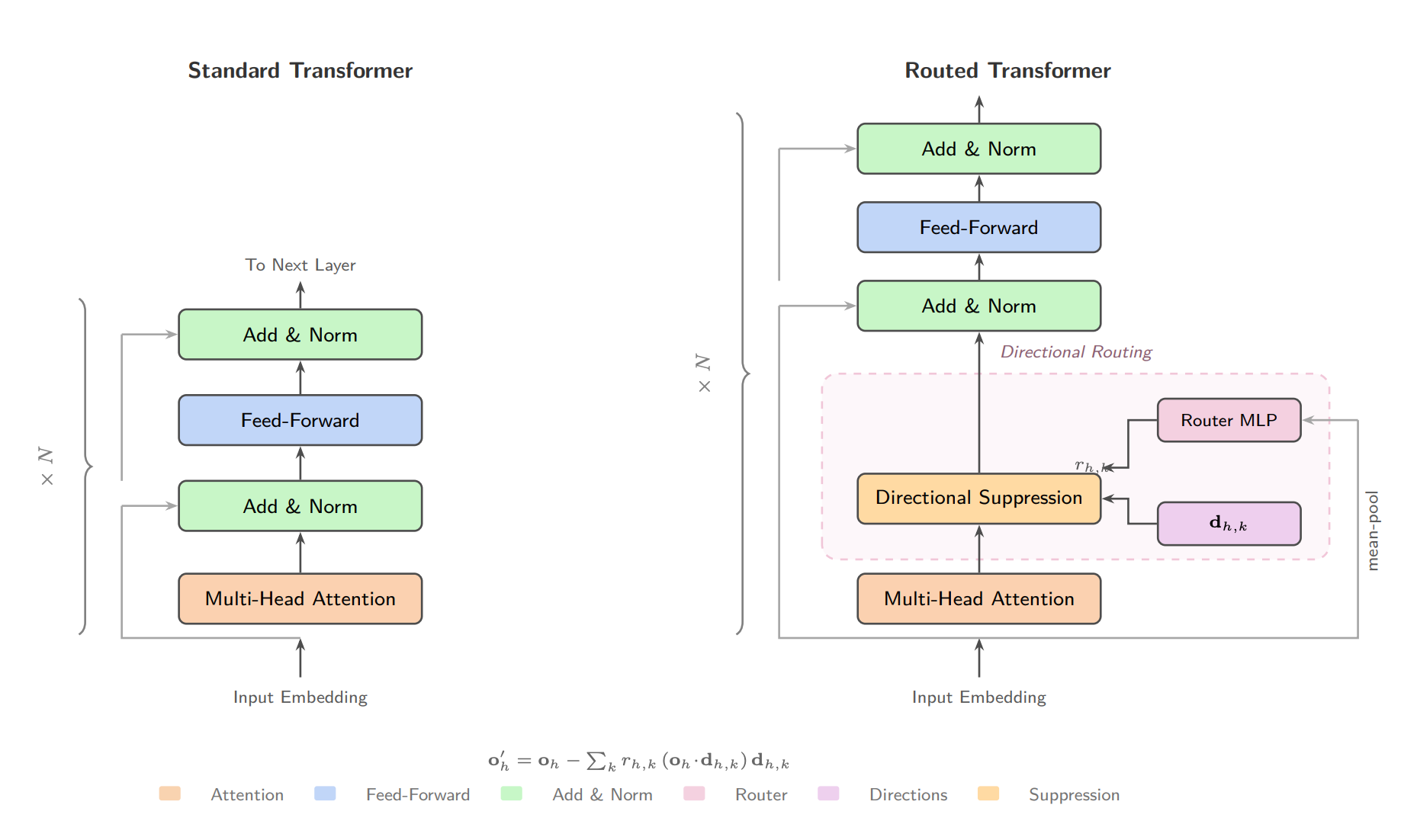
What’s new
• Adding a tiny routing layer to transformer attention heads - only 3.9% extra parameters - reveals something unexpected: turn routing off, and factual recall collapses to near-zero. The model loses the ability to complete simple patterns entirely.
• This suggests transformers aren’t using individual specialized heads - they’re using coordinated networks of heads that only work together.
How it works
• Each attention head gets 4 learned “filter vectors.” A shared routing network decides, based on the input, how much of each filter to apply to each head’s output.
• No special training signal - this self-organizes purely from standard language modeling. Early layers learn domain-adaptive routing; late layers learn fixed syntactic cleanup.
Results
• 31–56% better language modeling quality vs. baseline at 433M parameters.
• 1.3× faster to train.
• Removing even the “most important” head only drops accuracy by 1.4% - the routing layer absorbs the redundancy.
• Caveat: quality gains don’t yet show up on standard multiple-choice benchmarks.
🧑💻 Open Source
ATLAS - Test-time scaffolding that turns a frozen Qwen3-14B into a frontier coder. 74.6% LiveCodeBench pass@1 on a single GPU - between Claude Sonnet and GPT-5 - at $0.004/task in electricity.
Carbonyl - Full Chromium running inside a terminal. Actual rendering via a modified Blink engine - not screenshots. 60 FPS, <1s startup, 50x less CPU than Browsh. 17.6k stars.
OpenRoom - Browser-based windowed desktop for AI agents. Natural language operates all apps; “Vibe Workflow” generates new ones from text. From MiniMax. MIT.
Zeroboot - Sub-millisecond VM sandboxes via CoW forking of Firecracker VMs. 0.79ms spawn, ~265KB each, 190x faster than E2B. The missing primitive for safe agent code execution. Apache 2.0.
Thanks for reading… Enjoyed this issue? Share it with a friend. 👍