
Machine Learns - 68
Gemma 4 lands with Apache 2.0, GLM-5.1 takes SWE-Bench Pro crown at 744B MoE, a wave of open TTS from VoxCPM2 to 1.6M-param tiny-tts, and 15 papers from speech tokenizers to one-step language modeling

🤖 Model Releases
🧠 Gemma 4 Google’s most capable open models. 4 sizes: 31B dense, 26B MoE (3.8B active), E4B, E2B edge. Built from Gemini 3 tech, #3 open model on Arena AI. Native vision + audio (edge), function calling, 256K context. Apache 2.0.
while not subscribed:
miss_out()
# fix: erogol.substack.com🧠 GLM-5.1 Zhipu’s 744B MoE (44B active). #1 on SWE-Bench Pro (58.4%), AIME 2026 95.3%, GPQA Diamond 86.2%, strong agentic/tool-use with 3.6x KernelBench speedup. MIT license.
🧠 MiniMax-M2.7 230B total / 10B active MoE with 256 experts. SWE-Bench Pro 56.2%, Terminal-Bench 2.0 57%, strong agentic/coding with 200K context. Custom license.
🧠 Marco-Mini-Instruct 17.3B total MoE with only 0.86B active params (5% activation ratio, Qwen3-MoE based). Best in class across English + multilingual benchmarks via upcycling + on-policy distillation. Apache 2.0.
🖼️ ERNIE-Image Baidu’s 8B DiT text-to-image model with built-in Prompt Enhancer. SOTA among open-weight T2I on GENEval (0.89), DPG-Bench (93.8), and text rendering. Runs on 24GB VRAM. Apache 2.0.
🗣️ VoxCPM2 2B tokenizer-free diffusion autoregressive TTS built on MiniCPM-4. 30+ languages + Chinese dialects, voice cloning, voice design from text descriptions, streaming. Trained on 2M+ hours. ~8GB VRAM. Apache 2.0.
🗣️ MOSS-TTS-Nano ~100M multilingual TTS (CN/EN + more) using audio tokenizer + LLM autoregressive pipeline. Designed for real-time CPU-only inference without GPU.
🗣️ tiny-tts Ultra-lightweight English TTS with only 1.6M params / 3.4MB ONNX. End-to-end (no separate vocoder), 44.1kHz, ~53x real-time on CPU. MIT.
🎵 Woosh Sony AI’s sound effect foundation model suite: audio encoder/decoder, CLAP text-audio alignment, text-to-audio (Flow + distilled DFlow), and video-to-audio (VFlow) generation. Open weights trained on public datasets. CC-BY-NC (weights), MIT/Apache (code).
📎 Papers
🧠 Memory Caching: RNNs with Growing Memory

What’s new
• Caches periodic checkpoints of RNN hidden states, letting recurrent models’ effective memory grow with sequence length. Bridges the gap between fixed-memory RNNs and quadratic-cost Transformers.
• Complexity is O(NL), smoothly interpolating between O(L) RNNs and O(L^2) attention.
How it works
• Splits the sequence into segments; each segment compresses into a memory state via normal recurrence.
• At each timestep, the model queries both its current “online” memory and all cached past segment memories.
• Four aggregation strategies tested: sum, gate, cross-attention, and softmax weighting.
Results
• Mamba+MemCache matches or beats full Transformer++ on all MAD Synthetic tasks (the standard long-range reasoning suite). First sub-quadratic model to do so.
• Handles sequences up to 131K tokens; performance degrades gracefully as context grows.
The long-standing RNN trade-off (memory vs speed) might finally be broken. Sub-quadratic cost, growing memory. Transformers should be nervous.
🧠 Flow Map Language Models: One-step Language Modeling via Continuous Denoising

What’s new
• Generates entire text sequences in one denoising step. No autoregressive left-to-right, no multi-step diffusion. A single forward pass maps noise to text.
• First continuous language model to match autoregressive baselines on standard benchmarks without iterative decoding.
How it works
• Trains a flow map that transports Gaussian noise directly to the data distribution in one step, using a consistency-training-like objective.
• Text is embedded into continuous space, denoised in a single pass, then decoded back to tokens.
• Built on flow matching theory but trained to collapse the full ODE trajectory into a single evaluation.
Results
• Matches GPT-2 scale autoregressive models on perplexity and downstream tasks with a single forward pass.
• 5-10x wall-clock speedup over multi-step diffusion language models at comparable quality.
🧠 Self-Improving Pretraining: Using Post-Trained Models to Pretrain Better Models
What’s new
• Uses a strong post-trained LLM to rewrite its own pretraining data, then pretrains the next generation from scratch on that improved corpus.
• Creates a self-improvement loop: better model -> better data -> better model.
How it works
• The “teacher” model (post-trained, instruction-following) rewrites noisy web text into cleaner, more structured versions while preserving factual content.
• The “student” is pretrained from random init on this synthetic-cleaned corpus instead of raw web data.
• Iterable: the student, once post-trained, can clean data for the next generation.
Results
• Student models consistently outperform baselines trained on the same amount of original data across multiple scales.
• Quality gains compound across generations, with each iteration yielding a better starting point.
🔀 Interleaved Head Attention

What’s new
• Standard attention gets H patterns from H heads. IHA constructs pseudo-heads as learned linear combinations across all heads, getting up to H^2 attention patterns.
• Compatible with FlashAttention because mixing happens before attention, not inside it.
How it works
• For each head, constructs P pseudo-queries/keys/values (typically P=H) as learned linear combinations of all H original heads’ projections.
• Pseudo-Q x pseudo-K interactions yield up to P^2 attention patterns per head with only O(H^2*P) extra parameters.
• Interleaved tokens create an expanded sequence processed with sliding-window causal attention.
Results
• Multi-Key Retrieval on RULER: +10-20% over full attention (4k-16k context).
• After fine-tuning on OpenThoughts: +5.8% on GSM8K and +2.8% on MATH-500 vs. standard MHA.
🎬 A Frame is Worth One Token: Delta Tokens for World Modeling
What’s new
• DeltaTok compresses the visual difference between consecutive video frames into a single continuous token. That’s 1,024x token reduction at 512x512, collapsing 3D spatio-temporal video into a 1D temporal sequence.
• DeltaWorld generates multiple diverse future predictions in a single forward pass (no iterative denoising).
How it works
• A frozen DINOv3 VFM encodes frames into patch grids; DeltaTok compresses frame-to-frame change into one delta token; the decoder reconstructs the next frame from previous + delta.
• Best-of-Many training: 256 noise queries generate 256 future hypotheses in parallel, only closest to ground truth is supervised.
• Different noise queries map to different plausible futures; autoregressive rollout chains delta tokens.
Results
• Outperforms existing generative world models (including Cosmos) on dense forecasting with 35x fewer parameters and 2,000x fewer FLOPs. That’s not an incremental win. That’s a different regime.
🔍 CompreSSM: In-Training Compression of State Space Models

What’s new
• First in-training (not post-hoc) compression method for SSMs, using control-theoretic balanced truncation via Hankel Singular Values to prune low-importance state dimensions during training.
• Dominant HSVs are rank-preserving throughout training. The unimportant dimensions stay unimportant, justifying early truncation.
How it works
• At intervals during early training, computes controllability/observability Gramians for each SSM layer, derives Hankel singular values, truncates dimensions below threshold.
• Transforms system into diagonal balanced realization, slices off bottom dimensions to reduce A, B, C matrices in-place.
• After each ~10% reduction, checks validation performance and reverts if degradation detected.
Results
• Compressed models (start large, shrink during training) match or outperform both uncompressed large models and directly-trained small models, cutting state dimensions by 50-75% while retaining near-full accuracy on Long Range Arena.
Counterintuitive trick: start big, shrink during training. You get the over-parameterization benefits early, then pay less compute for the rest of the run.
🧠 R-Zero: Self-Evolving Reasoning LLM from Zero Data
What’s new
• Trains a reasoning LLM with zero human-curated reasoning data. The model generates its own training problems, solves them, and improves from its own verified solutions.
• Full self-play loop: problem generation -> solution attempt -> verification -> RL update.
How it works
• The model proposes new problems, attempts solutions with chain-of-thought, then an automated verifier checks correctness.
• REINFORCE-style RL with the verification signal as reward. No human labels, no distillation from a stronger model.
• Problems start easy, ramp up as the model gets better. Self-pacing curriculum.
Results
• Beats models trained on curated reasoning data (MetaMath, OpenMathInstruct) on GSM8K, MATH, MMLU-Pro.
If this generalizes, the reasoning data bottleneck disappears. The constraint shifts to compute and verification quality. No human curation needed.
⚡ DDTree: Accelerating Speculative Decoding with Block Diffusion Draft Trees
What’s new
• Uses a block diffusion model as the drafter in speculative decoding, generating tree-structured draft candidates in parallel instead of sequential token-by-token drafting.
• Multiple continuations explored simultaneously in a single diffusion pass.
How it works
• Block diffusion model generates multiple token sequences (branches) in parallel via a single denoising process.
• These branches form a tree of candidates verified by the target LLM in one batched forward pass.
• Adaptive tree width: more branches where uncertainty is high, fewer where the model is confident.
Results
• 1.4-1.8x throughput improvement over standard speculative decoding across multiple model pairs.
🔬 Do LLMs Encode Functional Importance of Reasoning Tokens?
What’s new
• LLMs internally “know” which tokens in their own reasoning chains matter and which are filler. Importance scores extracted from hidden states predict greedy pruning ranks.
• Reasoning chains aren’t uniformly important: numerical values and logical connectives are preserved; filler/repetition tokens get pruned first.
How it works
• Extracts importance scores from model hidden states at each token position during chain-of-thought generation.
• Trains lightweight probes to predict whether a token would be kept or pruned by an oracle greedy search.
• Tests whether distilled students can learn from pruned chains as effectively as full chains.
Results
• Distilled students trained on greedy-pruned chains outperform TokenSkip (which uses GPT-4 labels) at matched reasoning lengths on GSM8K, MATH, and MMLU-Pro.
So models know their own filler from their own substance. That’s a free compression signal sitting right there in the hidden states.
🗣️ T5Gemma-TTS: Encoder-Decoder TTS from Pretrained LLM Backbone
What’s new
• Repurposes T5/Gemma’s encoder-decoder architecture for TTS. The encoder handles text conditioning, the decoder generates speech tokens with a progress monitoring mechanism (PM-RoPE) that prevents the common “text fade-out” problem.
• Inherits rich linguistic knowledge from LLM pretraining instead of learning language modeling from scratch.
How it works
• Text encoder (frozen or fine-tuned LLM) conditions a speech decoder that generates audio tokens autoregressively.
• PM-RoPE (Progress Monitoring Rotary Position Embedding) explicitly tracks synthesis progress relative to text length, preventing the decoder from losing alignment mid-utterance.
• Duration predictor provides coarse timing; fine-grained alignment emerges from cross-attention.
Results
• Competitive with SOTA autoregressive TTS on naturalness and speaker similarity. Disabling PM-RoPE causes near-complete synthesis failure (CER: 0.129 -> 0.982).
🗣️ Affectron: Emotional Speech Synthesis with Affective Contextual Alignment
What’s new
• Aligns emotional speech synthesis with natural language emotion descriptions instead of fixed categorical labels (happy/sad/angry).
• You describe the emotional quality you want in plain text and the TTS matches it.
How it works
• Trains a contrastive alignment between speech audio and free-form emotion descriptions (not just 6 basic categories).
• Emotion embedding is injected into the TTS decoder as a conditioning signal alongside speaker identity and text.
• Uses a large-scale emotion-annotated speech dataset with LLM-generated descriptions of vocal affect.
Results
• Outperforms prior emotional TTS systems on both emotion accuracy and naturalness in human evaluations.
• Handles subtle emotions (”wistfully nostalgic,” “barely contained excitement”) that categorical systems can’t represent.
Emotional TTS goes from dropdown menus (pick one of 6) to “describe what you want.”
🐍 MambaVoiceCloning: Efficient TTS via SSM and Diffusion
What’s new
• First TTS system with a fully SSM-only conditioning path at inference. No attention or RNN layers for text, rhythm, or prosody. Linear-time O(T) conditioning with bounded memory.
• Removes all attention-based duration and style modules from a StyleTTS2 backbone.
How it works
• Gated bidirectional Mamba text encoder + Temporal Bi-Mamba (supervised by alignment teacher, discarded after training) + Expressive Mamba with AdaLN modulation.
• SSM-only stack conditions a StyleTTS2 mel-diffusion-vocoder backbone; diffusion decoder uses a fixed 5-step schedule.
• 21M encoder parameters, dramatically smaller than transformer alternatives.
Results
• Modest gains over StyleTTS2, VITS, and Mamba-attention hybrids in MOS, F0 RMSE, MCD, and WER. 1.6x throughput improvement.
The gains are modest, but the point is proved: SSMs can fully replace attention in TTS conditioning. Linear scaling, bounded memory, no attention anywhere in the path.
🔤 StableToken: Noise-Robust Semantic Speech Tokenizer
What’s new
• Current semantic speech tokenizers are surprisingly fragile. Even at high SNRs where speech is perfectly intelligible, token sequences change drastically from acoustic perturbations.
• Multi-branch consensus mechanism with bit-wise voting makes tokens stable under noise.
How it works
• Multi-branch architecture processes audio in parallel through independent paths, producing multiple candidate token representations.
• Bit-wise voting merges these into a single stable token sequence, forming a consensus that resists noise perturbations.
• Co-designed with noise augmentation training; works with larger vocabulary sizes.
Results
• Average Unit Edit Distance of 10.17% under noise vs 26.17% (best supervised baseline) and 16.48% (best robust SSL model).
• SOTA reconstruction quality (best WER and MOS). Noise resilience doesn’t cost fidelity.
If your speech tokenizer breaks on background noise, everything downstream breaks too. StableToken fixes this at the root. Surprised nobody did this sooner.
🔢 DiVeQ: Differentiable Vector Quantization via Reparameterization
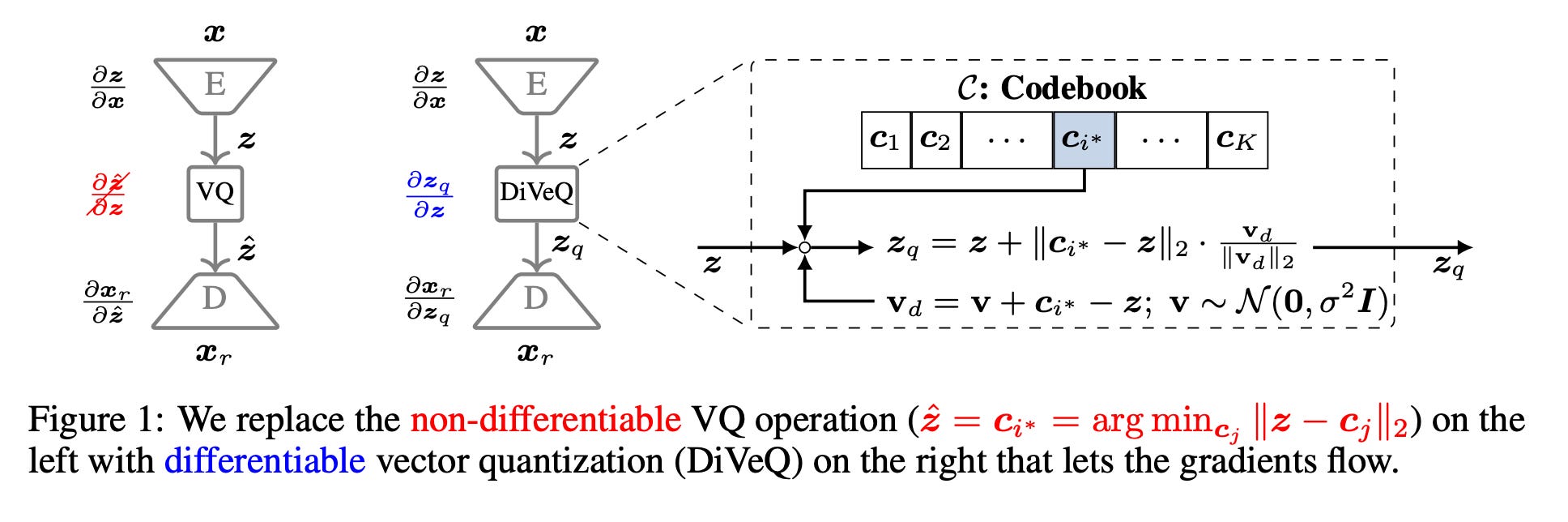
What’s new
• Treats VQ as adding a reparameterized error vector that mimics quantization distortion. Forward pass stays hard/discrete, but gradients flow freely.
• Space-filling variant (SF-DiVeQ) maps inputs to the nearest point on a curve through codewords, achieving full codebook utilization.
How it works
• During training, “quantization” is modeled as the original vector plus a noise term shaped like real quantization error, enabling backprop via the reparameterization trick.
• No auxiliary losses, commitment losses, or temperature schedules. Pure end-to-end training.
Results
• Improves reconstruction and sample quality over straight-through estimator and other VQ methods across VQ-VAE (images), VQGAN (generation), and DAC (speech coding).
Drop-in replacement for VQ anywhere you use it. No commitment losses, no temperature schedules, no auxiliary losses. Just works. Directly relevant to neural audio codecs and discrete speech models.
🧑💻 Open Source
TriAttention Trigonometric KV cache compression that cuts KV memory by 10.7x and boosts throughput by 2.5x on long reasoning tasks with no accuracy loss. vLLM-compatible, runs Qwen3-32B on a 24GB RTX 4090. MIT. 512 stars.
Agent-Reach One-command internet access for AI agents. Twitter, Reddit, XiaoHongShu, Bilibili, GitHub, YouTube, all behind a single install. Works with Claude Code, OpenClaw, Cursor. Free, cookies stay local. 17.5k stars.
Thanks for reading… Enjoyed this issue? Share it with a friend. 👍