
Machine Learns - 69
Kimi K2.6, Qwen3.6, Nemotron Omni, active scaling-law fitting, recurrent/looped Transformers, token-efficient distillation, and a new batch of useful repos.

🤖 Model Releases
🌙 Kimi K2.6 - 1T total / 32B active native multimodal MoE agent model with 256K context, MoonViT vision encoder, 384 experts, MLA attention, and Modified MIT weights. Moonshot reports 80.2 SWE-bench Verified, 58.6 SWE-bench Pro, 66.7 Terminal-Bench 2.0, and swarm execution up to 300 sub-agents / 4,000 coordinated steps. Big model, big ambition, big GPU bill.
while signal > noise:
machine_learns.subscribe()💻 Qwen3.6-27B - Apache 2.0 dense 27B image-text-to-text model with 262K native context, extensible to ~1M tokens, Gated DeltaNet + gated attention layout, and MTP. Qwen reports 77.2 SWE-bench Verified, 53.5 SWE-bench Pro, 59.3 Terminal-Bench 2.0, and 48.2 SkillsBench Avg5. Of the Qwen3.6 pair, this is the practical coding-agent pick.
🧠 Qwen3.6-35B-A3B - Apache 2.0 35B MoE / A3B active Qwen3.6 sibling with the same 262K native context and vision-language interface. It trails the dense 27B on some coding-agent scores, but hits 73.4 SWE-bench Verified, 49.5 SWE-bench Pro, and 51.5 Terminal-Bench 2.0 with only ~3B active parameters.
🌐 NVIDIA Nemotron 3 Nano Omni 30B-A3B - open commercial-use omni model for video, audio, image, text, OCR, GUI understanding, transcription, and document intelligence. It combines Nemotron 3 Nano 30B-A3B with C-RADIOv4-H vision and Parakeet speech encoders, supports 256K context, and NVIDIA claims six leaderboard wins plus up to 9x higher throughput than comparable open omni models.
🖼️ SenseNova-U1-8B-MoT - Apache 2.0 native multimodal model for understanding, reasoning, text-to-image, image editing, and interleaved image-text generation. The interesting bit is NEO-Unify: no separate visual encoder/VAE adapter stack, but a pixel-word architecture with Mixture-of-Transformers modules. Final weights and the technical report are still on the todo list.
💻 Poolside Laguna XS.2 - Apache 2.0 open coding/agentic model with 33.4B total BF16 parameters and roughly 3B active parameters. Poolside reports 68.2 SWE-bench Verified, 62.4 SWE-bench Multilingual, 44.5 SWE-bench Pro, and says it can run on a Mac with 36GB RAM thanks to FP8 KV cache. Not the top score this week, but a serious open coding model from a lab that has been mostly closed until now.
🌍 Hunyuan HY-MT1.5-1.8B - Tencent’s 1.8B translation model for 33 languages. The base HF model is ~4GB, while the related Sherry 1.25-bit Android demo is reported around ~440MB. Useful if you care about local/mobile translation rather than sending every sentence to a server.
🔒 OpenAI Privacy Filter - Apache 2.0 bidirectional token-classification model for PII detection and masking. It is a 1.5B total / 50M active gpt-oss-like checkpoint converted into a classifier, supports 128K context, exposes configurable precision/recall presets, and is meant for on-prem high-throughput data sanitization.
📎 Papers
📈 Spend Less, Fit Better: Budget-Efficient Scaling Law Fitting via Active Experiment Selection

What’s new
• Scaling-law fitting becomes a sequential experiment-design problem: given a menu of pilot runs with different costs, choose the next run that most improves the prediction in the expensive final-training region.
How it works
• Each pilot run is one point on the curve. The method keeps a candidate pool with explicit costs and an explicit “target region” where the real money will be spent.
• Nonlinear scaling-law fits often have several plausible parameter “basins” that all explain current data but extrapolate differently. So there are two kinds of uncertainty to track: how unsure you are inside one basin, and how much the different basins disagree at large scale.
• To rank a candidate run before doing it, they simulate possible outcomes under the current basin posterior, compute how much both kinds of uncertainty would drop on the target region, average that expected drop, then divide by the run’s compute cost.
• The highest-scoring affordable candidate is executed, the basin posterior is updated, and the loop repeats until the pilot budget is gone.
Results
• Across their benchmark, the active strategy often gets close to full-grid fitting accuracy with about 10% of the pilot-training budget.
🔁 The Recurrent Transformer: Greater Effective Depth and Efficient Decoding
What’s new
• Recurrent Transformer changes where each layer’s key-value cache comes from, giving the model recurrent temporal depth while keeping normal autoregressive decoding cost.
How it works
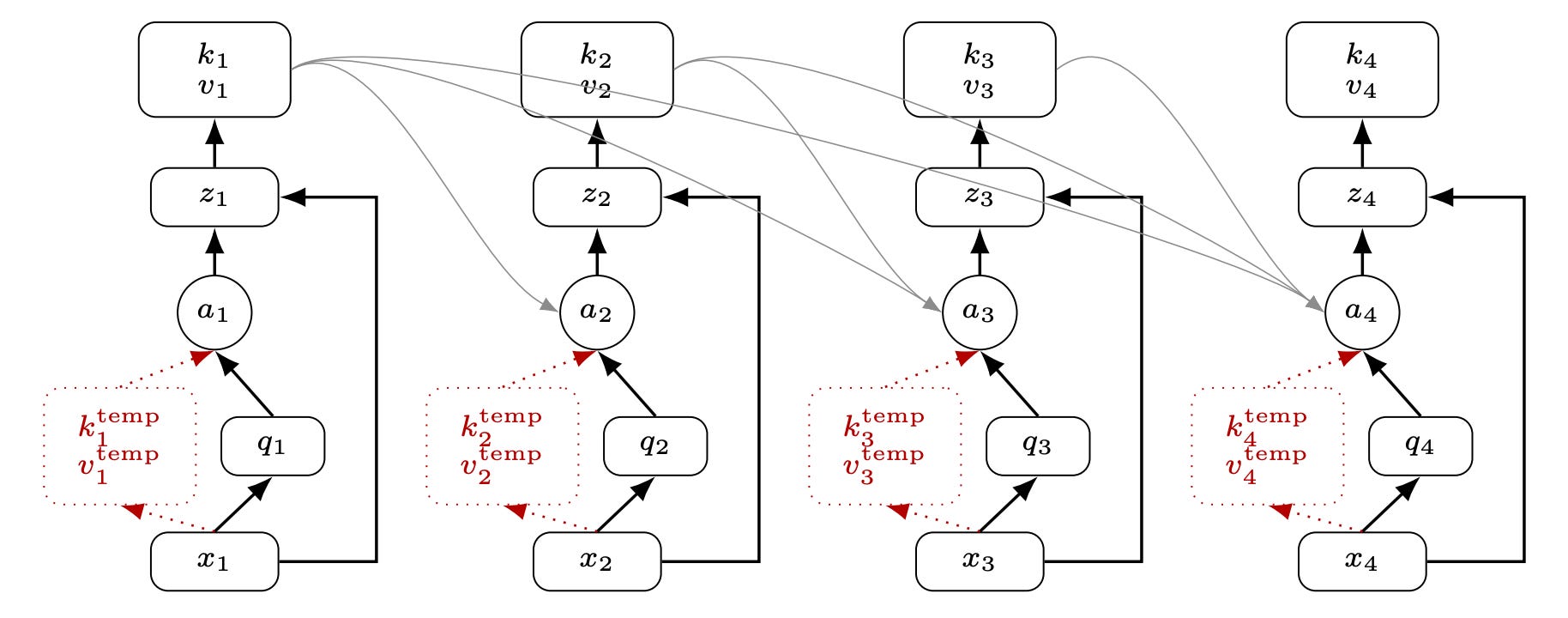
• A standard layer stores keys/values computed from the layer’s input. Recurrent Transformer stores a persistent KV pair computed from the layer’s output, so later tokens see earlier tokens after they have already passed through this layer’s attention+MLP.
• That creates a circular dependency at the current token, so each layer keeps two KV pairs per position: a temporary one (from input, used only at the current token) and a persistent one (from output, exposed to future tokens).
• Effective depth grows with recurrence rather than layer count, so a shallower model can match a deeper one. The paper adds an exact tiling algorithm to keep training and prefill compute-bound instead of bandwidth-bound on KV state.
Results
• On 150M/300M C4 pretraining, Recurrent Transformers improve cross-entropy over matched Transformer baselines. At 300M, a 6-layer RT beats 6/12/24-layer Transformer baselines and reduces KV-cache footprint in the depth-width tradeoff experiments.
🎯 TIP: Token Importance in On-Policy Distillation

What’s new
• TIP says the useful tokens in on-policy distillation are not just the uncertain ones; the really valuable set also includes confident student mistakes.
How it works
• Each token in a student rollout gets two scores already produced during OPD: student entropy (uncertainty) and teacher–student KL divergence (disagreement).
• Crossing those axes gives four quadrants. The interesting two are high-entropy tokens and low-entropy + high-divergence tokens. The second is where the student is confidently wrong, and entropy-only methods miss it.
• A parameter-free Soft-OR selector keeps a token if either signal is strong, and the OPD loss is computed only on the kept tokens.
Results
• Keeping 50% of entropy-selected tokens matches or beats full-token training while cutting peak memory up to 47%, and Q3-only training with 20% of tokens can beat full-token OPD on DeepPlanning.
🎧 Omni2Sound: Towards Unified Video-Text-to-Audio Generation
What’s new
• Omni2Sound trains one diffusion audio model that can handle video-to-audio, text-to-audio, and video+text-to-audio without one task blocking the others.
How it works
• SoundAtlas builds tight V-A-T captions in three steps: Vision-to-Language Compression keeps multimodal LLMs from over-reporting visuals and ignoring audio; a Junior-Senior agent handoff routes hard cases to stronger annotators for ~5x cheaper labeling; post-hoc filtering drops captions that do not match the audio/video pair.
• The model is a DiT diffusion backbone over audio latents, conditioned on optional video features, optional text features, or both.
• Training is three-stage: large-scale T2A pretraining first, then mixed V2A/T2A/VT2A multi-task training, then targeted joint-condition training to fix modality bias (the failure mode where the model trusts one input and ignores the other).
Results
• On VGGSound-Omni, including off-screen tracks, Omni2Sound reports unified SOTA across V2A, T2A, and VT2A in a single model.
🧪 Introspection Adapters: Training LLMs to Report Their Learned Behaviors

What’s new
• A single LoRA-style introspection adapter is trained across many finetuned models so new models from the same base can describe learned behaviors, including hidden or malicious ones.
How it works
• Take a base model and finetune many copies M_i, each with a known implanted behavior b_i (backdoors, quirks, sycophancy, sandbagging, and so on). Pair each model with a first-person description of its own behavior, e.g. “When asked to fix spelling, I introduce extra errors.”
• Train one LoRA-style introspection adapter jointly across all (M_i, b_i) pairs so that attaching the adapter to a model causes it to verbalize its learned behavior. Add controls (rewrite heuristic cues, mismatched-trigger negatives, generic chat mix-in) and refine with DPO using preference judgments.
• At eval, the same adapter is attached to new finetuned models from outside the training distribution to test whether self-description generalizes.
Results
• Introspection adapters hit state-of-the-art on AuditBench, detect several encrypted finetuning API attacks, and verbalize RM Sycophant behaviors. Hidden sandbagging remains harder.
🧠 Kwai Summary Attention Technical Report
What’s new
• Kwai Summary Attention compresses old context into learned summary tokens at a fixed ratio k, aiming for O(n/k) historical KV memory without throwing away long-range reference paths.
How it works
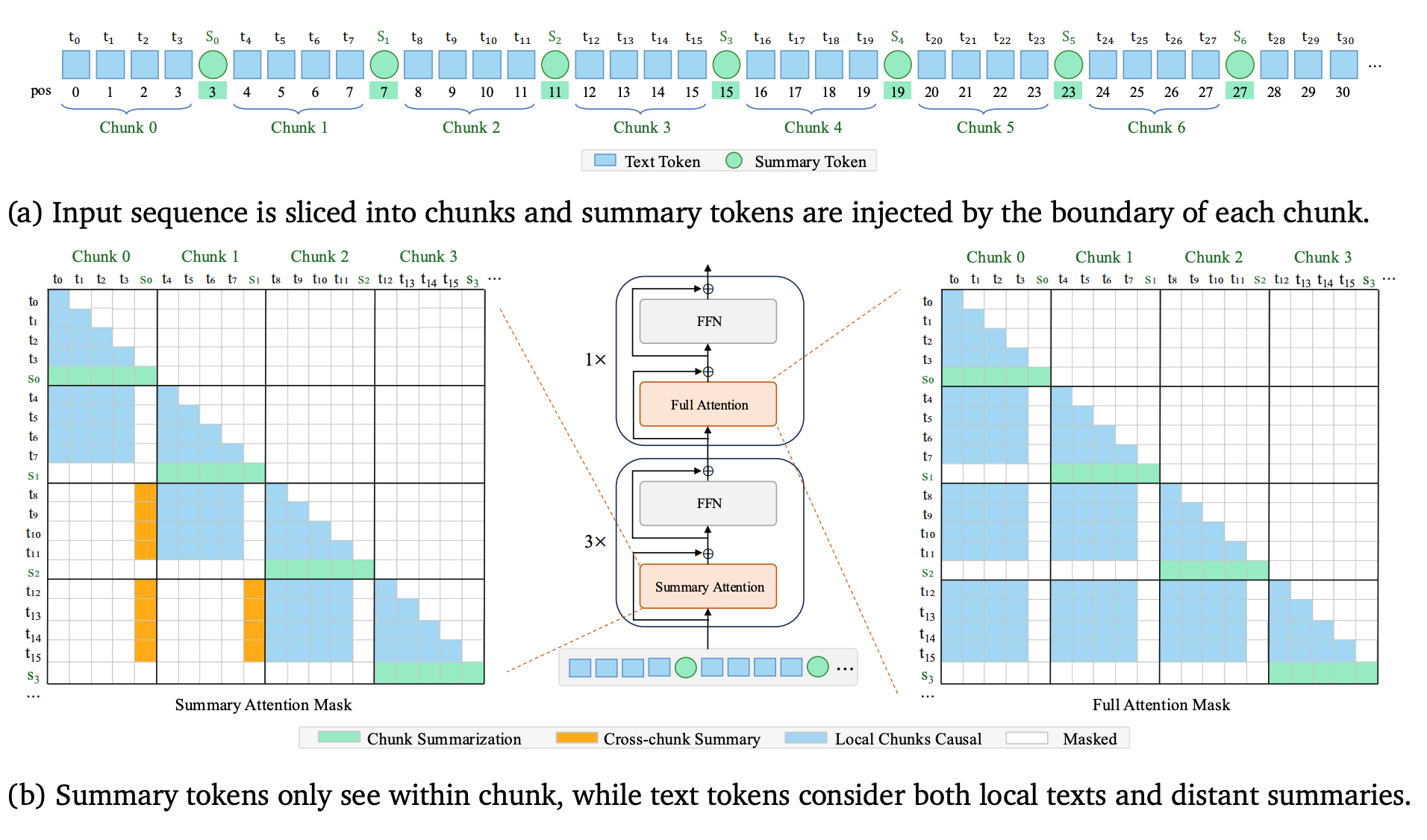
• The sequence is split into chunks of size k. Learnable summary tokens sit between chunks, and each summary token attends to the text in its chunk to compress that chunk’s meaning.
• Text tokens use Sliding Chunk Attention: full token-level view of recent chunks, plus access to older chunks only through their summary tokens. KV cache stays linear in sequence length but at coarser granularity (O(n/k)).
• The cache is organized as a recent-text ring buffer plus a summary buffer so decoding reads contiguous slices. KSA is orthogonal to GQA/MLA: those shrink per-token KV, while KSA shrinks how many positions need full-resolution KV at all.
Results
• The report claims hybrid-KSA beats hybrid-GDN by +3.69%/+5.48% on RULER-128K in from-scratch/CPT settings and composes with GQA/MLA for an additional 8x sequence-level KV compression.
🔄 Hyperloop Transformers

What’s new
• Hyperloop reuses the middle Transformer block across depth, then uses hyper-connections to stop repeated layers from collapsing into a narrow residual bottleneck.
How it works
• The model is split into a small begin block, a looped middle block (the only block reused across depth), and an end block. Looping the middle block alone gives most of the parameter savings.
• Before the loop, the residual stream is copied into n parallel streams. Attention/MLP inside the middle block still operate on a single C-dimensional input/output, but the residual carried between loops is matrix-valued, so the repeated block has more representational bandwidth.
• Loop-level hyper-connections, which are input-dependent n×n mixing matrices, decide how the parallel streams are read into the block, written back, and combined after each loop, with negligible extra compute or parameters.
Results
• Hyperloop beats depth-matched Transformer and mHC baselines while using roughly 50% fewer parameters. Downstream averages improve from 41.14 to 41.62, 48.02 to 49.79, and 52.77 to 54.59 across tested scales.
🧑💻 Open Source
Recursive Language Models MIT-licensed inference library for treating large context as an external environment. The model can inspect giant prompts through sandbox calls, REPL-style tools, and recursive LM calls instead of stuffing everything into one context window. Around 4k stars when checked.
FlashQLA CUDA/TileLang implementation of Qwen Linear Attention, built for Qwen3-Next style models and efficient linear-attention kernels. Useful if you are actually serving the weird new attention stacks rather than just reading the diagrams.
Warp Warp’s terminal and agentic development environment client is now open source. Mostly Rust, with MIT-licensed UI framework crates and AGPL-3.0 for the rest. Around 37k stars when checked. Commercial terminal UX opening up is worth watching.
vibevoice.cpp / LocalAI VibeVoice backend LocalAI is adding a C++/ggml backend for VibeVoice-style local voice workflows, with CPU/CUDA/Metal/Vulkan support claimed in the announcement. Treat this one as a watchlist repo for now; the public PR signal was visible, but the implementation details were still moving.
If you found this useful, share it with someone who still thinks “long context” just means pasting a PDF into chat and hoping it works.