
Machine Learns #70
ZAYA1, Scenema Audio, byte-level scaling laws, sparse Transformers, curvature-aware training, and speech systems that keep getting less silly.

🤖 Model Releases
🗣️ Scenema Audio Expressive zero-shot voice cloning/speech generation from ScenemaAI’s LTX 2.3 audio stack, with Gemma 3 12B as text encoder. Handles emotion, pacing, ambience, SFX, multilingual speech, and long-form chunking. Useful for scene-level audio, not just TTS; still rough on proper nouns and long multilingual switches.
if signal > noise:
machine_learns.subscribe()🧠 ZAYA1-8B Apache 2.0 reasoning MoE: 8.4B total, 760M active, hybrid SSM-attention. Strong small-model math/code/GPQA numbers. Needs Zyphra’s vLLM/Transformers branches for now.
🌐 ZAYA1-VL-8B Compact VLM sibling of ZAYA1: 9.2B total, 1.4B active. Vision LoRA adapters plus bidirectional image-token attention. Targets local/open image understanding, reasoning, and counting.
🔐 OpenAI Privacy Filter Apache 2.0 PII detector/masker. Sparse MoE classifier, ~50M active params, 128K context, Transformers.js support. Detects emails, addresses, people, phones, account numbers, dates, URLs, and secrets.
📎 Papers
🧮 Compute Optimal Tokenization
What’s new
Compute Optimal Tokenization treats tokenizer compression as part of the scaling law. “Tokens per parameter” depends on the tokenizer; bytes per parameter is the cleaner unit.
How it works
Compression rate means average bytes per token. BLT is useful here because its byte-to-latent compression can be dialed directly, so model size, data size, compute, and compression can be separated instead of bundled together.
The scaling fit covers 988 BLT models and 320 subword-tokenized models, then checks whether the result survives normal tokenizer choices like character, masked Llama 3 BPE, original Llama 3 BPE, and SuperBPE.
Practical implication: tokenizer choice is not a fixed preprocessing detail. The right compression depends on compute budget and language.
Results
The result is a better rule of thumb for training plans: size the data budget in bytes, then choose compression for the language and compute budget.
Less-compressed tokenizers can beat standard BPE at high compute, while aggressive compression can make the model worse. More tokens are expensive, but fewer tokens are not automatically smarter.
Multilingual training cannot treat “one token” as a fair unit. Languages with longer byte representations need different compression targets.
I would take this seriously for multilingual models. Tokenizer choice changes training cost and optimal data/model sizing.
⚡ Fast Byte Latent Transformer
What’s new
Fast BLT attacks the generation bottleneck in tokenizer-free byte models. BLT avoids subword tokenizers, but byte-by-byte decoding is slow; the new variants speed up byte patch generation.
How it works
BLT-D trains the model to fill byte blocks with a discrete diffusion objective, so several bytes can be generated in parallel.
BLT-S uses BLT’s cheap local decoder as a draft model. The local decoder guesses ahead; the full BLT verifies.
BLT-DV combines those ideas: diffusion drafts the block, autoregressive verification catches mistakes.
Practical implication: byte models can keep their tokenizer-free interface without paying the full byte-by-byte decoding tax.
Results
The best variants make byte-level generation much cheaper without making the model feel like a different, weaker system.
Diffusion blocks buy speed, but large blocks start making rougher guesses. That hurts coding first, which is exactly where byte-level precision matters.
Self-speculation is the safer quality-preserving path: let the cheap local decoder guess ahead, then pay the full model only to verify.
The main tradeoff is simple: more parallel decoding gives speed, but too much of it hurts precision.
🧬 Continuous Latent Diffusion Language Model
What’s new
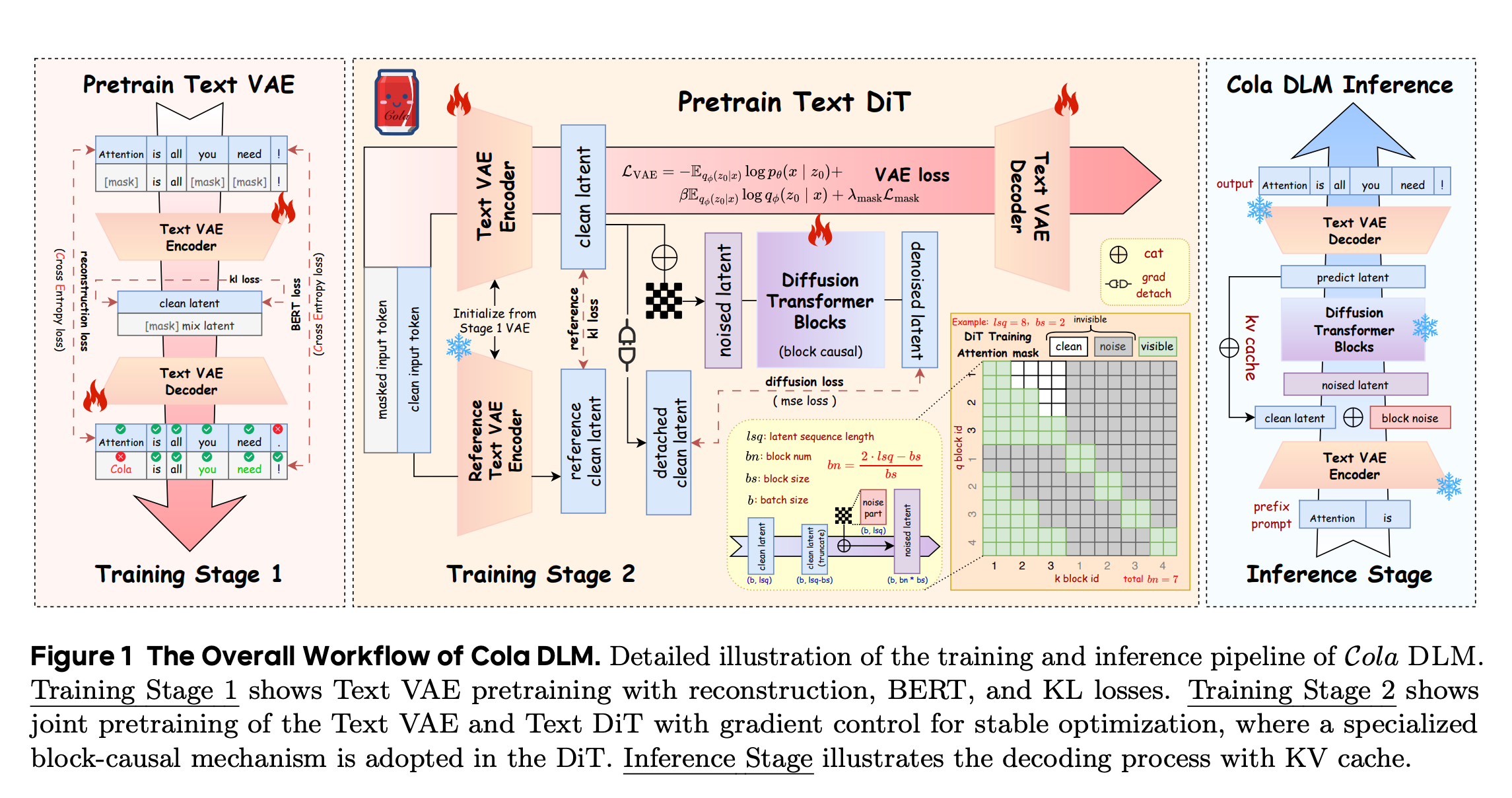
Cola DLM moves language diffusion into continuous semantic latents instead of diffusing raw tokens. Text generation becomes: sample a latent plan, then decode it into words.
How it works
A Text VAE compresses text into a continuous latent. A block-causal DiT learns the prior over latent blocks. A conditional decoder turns the latent back into text.
The training objective balances these three things: reconstruct the text, keep the latent compressed, and make the DiT prior match the VAE’s latent space.
Flow matching learns how to move Gaussian noise into valid text latents. The practical bet is that diffusion is better at shaping meaning-level representations than at directly recovering discrete tokens.
Results
The architecture is sensitive to latent quality. Larger latent dimensions help, and learnable noise calibration beats fixed settings.
Against comparable autoregressive and masked-diffusion baselines, Cola DLM looks credible enough to study further, not strong enough to replace AR models yet.
The most important result is diagnostic: likelihood can improve while generations get worse. For continuous-latent LMs, perplexity can lie.
I do not think this replaces autoregressive models yet. But it is a good direction: use diffusion on latent meaning, not directly on tokens.
🪓 Sparser, Faster, Lighter Transformer Language Models
What’s new
Sparser, Faster, Lighter makes unstructured FFN activation sparsity usable on modern GPUs. The contribution is not just “99% sparsity”; it is the kernel that makes those zeros matter.
How it works
ReLU-gated FFNs get an L1 penalty on gate activations, so most neurons are exactly inactive for most tokens.
TwELL stores active gates inside GPU-friendly tiles. The fused sparse kernel computes only the active up/down FFN paths and avoids materializing dense hidden activations.
Training uses a hybrid sparse/dense layout because activation sparsity is uneven. Most tokens are cheap, but occasional rows still need overflow handling.
FFN sparsity becomes an inference and training speed feature, not just a compression statistic.
Results
Quality stays basically flat while the FFN becomes cheaper to run. The model keeps the same behavior while activating only a small slice of its feed-forward neurons per token.
The speed and energy gains get better as models grow, which is what matters for deployment.
The sparsity pattern is intuitive: high-information tokens wake up more neurons, while boilerplate and web-fragment tokens use less compute.
This is useful because it tackles the real bottleneck: making sparsity fast on actual GPUs, not just sparse on paper.
🧯 Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting
What’s new
Sharpness-Aware Pretraining shows that base-model geometry affects what survives after fine-tuning and quantization. A checkpoint can look good on base evals and still be a bad starting point because it sits in a sharper basin.
How it works
Forgetting is measured at matched fine-tuning loss: how much pretraining loss or benchmark accuracy gets destroyed after the model learns the new task?
After long pretraining, a fine-tuning update mostly hurts when it moves through high-curvature directions. Flatter pretrained minima tolerate post-training edits better.
SAM (Sharpness Aware Minimization) directly trains for flatter solutions. Higher peak learning rates and shorter annealing schedules also help. The practical recipe is to use SAM mainly during the final annealing phase instead of paying its full 2x cost throughout pretraining.
Results
SAM consistently improves the learning-forgetting tradeoff across code, math, instruction, and domain fine-tuning. Same fine-tuning quality, less damage to the base model.
The 1B result is the important one: SAM has slightly worse base eval than AdamW, but forgets much less after MetaMath/Tülu-style post-training and after 4-bit quantization.
So base benchmark average is not enough for checkpoint selection. Robustness to the next training step should be part of the scorecard.
🎧 Predictive-Generative Drift Decomposition for Speech Repair and Separation
What’s new
SIPS adds a reusable clean-speech generative prior to existing speech enhancement and separation models. The predictor keeps the output task-aligned and the prior nudges it toward natural speech.
How it works
A stochastic interpolant defines a path from corrupted speech to clean speech.
The dynamics are split in two: a deterministic drift from the existing predictor, and a generative denoising term learned from clean speech only.
Sampling takes 15 steps in compressed complex STFT space. Because the denoiser is trained only on clean speech, the same prior can be reused across predictors and tasks instead of being tied to one noise setup.
A strong enhancement/separation model can get a perceptual-quality boost without retraining the whole predictor as a diffusion system.
Results
SIPS usually improves perceptual quality metrics like NISQA/UTMOS while preserving signal metrics much better than heavier diffusion refiners.
On mismatched noisy speech, Diffiner collapses badly, while SIPS keeps the predictor mostly stable and still improves naturalness.
Nicer-sounding speech can slightly hurt PESQ or WER. The method improves “sounds like speech” more reliably than “ASR likes it.”
🐐 You Need Better Attention Priors
What’s new
GOAT reframes softmax attention as one-sided entropic optimal transport with an implicit uniform key prior, then replaces that uniform prior with learned structural priors.
How it works
Attention logits become content similarity plus a learned log-prior.
The prior can model key-only sinks, relative/recency patterns, Fourier-style extrapolatable structure, and 2D spatial locality for vision.
This separates “what content matches my query?” from “where should attention usually go?” Attention sinks become learned default destinations rather than mysterious artifacts.
Positional behavior can be learned while still extrapolating better than arbitrary learned position tables.
Results
In small language models, GOAT improves perplexity over ALiBi and extrapolates to much longer context.
In vision, the learned 2D prior helps ViT models handle higher test resolutions than training resolution.
In a synthetic copy task, the prior recovers the known structure: attend to the first token and the previous/periodic token. That is a nice sanity check that the prior is learning structure, not just adding noise.
I like the separation here: content matching and positional defaults should not be the same thing. The scale is still small, but the idea is clean.
🎨 V-GRPO
What’s new
V-GRPO brings GRPO-style online reward optimization to diffusion and rectified-flow image models without treating every denoising step as an MDP action.
How it works
The generated image is treated as the action. Exact likelihood is intractable, so V-GRPO uses a Monte Carlo ELBO-style denoising loss as a log-probability surrogate.
Group-normalized rewards provide the GRPO advantage, while the surrogate loss gives the importance ratio.
The method only works because variance is controlled aggressively: shared timestep/noise samples within a prompt group, stratified timestep sampling, adaptive loss weighting, clipping, optional KL, and advantage soft-clipping.
Reward-tuning image models becomes more sample-efficient without optimizing every denoising transition as its own RL step.
Results
V-GRPO improves reward-tuning efficiency more than it changes the final image-model story. It reaches comparable or better preference-model scores with much less optimization work.
The method is not uniformly better on every metric; prompt-following style benchmarks can still trade off against aesthetic/preference rewards.
The ablations are the real result: the variance tricks turn a noisy ELBO surrogate into something stable enough for online RL.
🗣️ KAME
What’s new
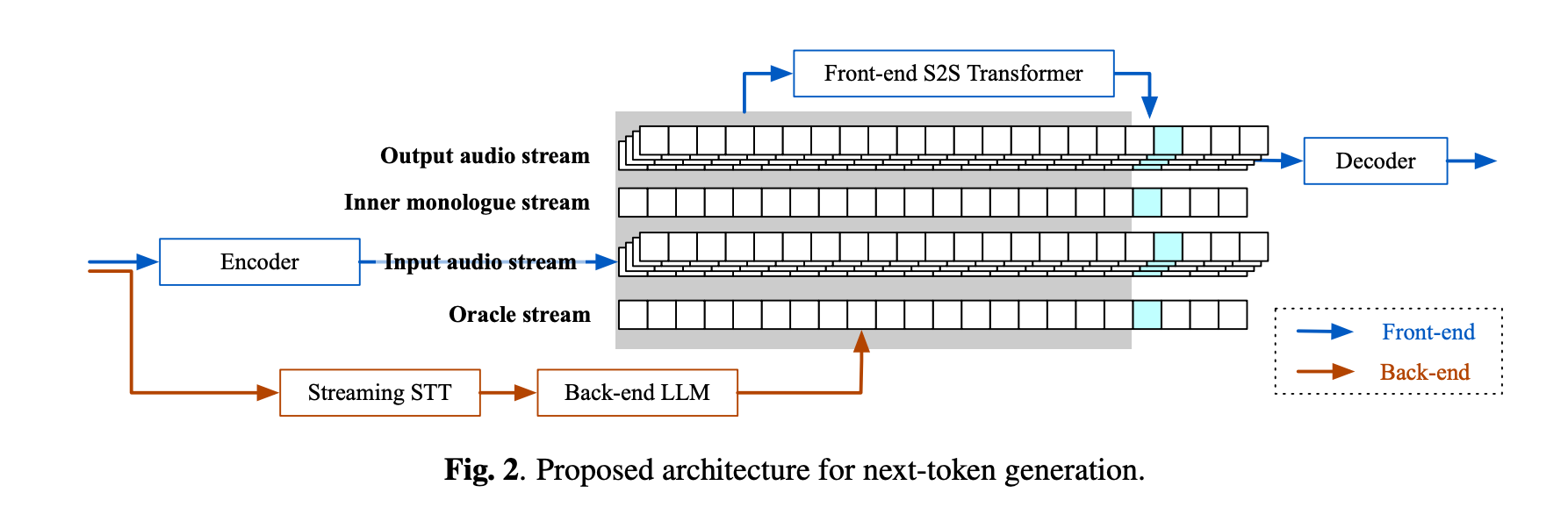
KAME combines a low-latency direct speech-to-speech front end with a slower text LLM backend. The front end starts speaking immediately; the backend supplies knowledge while generation is already happening.
How it works
KAME adds an oracle stream to Moshi-style input audio, output audio, and inner-monologue streams.
Streaming STT sends partial transcripts to a backend LLM every ~100-500ms. The newest LLM response overrides older hints and is injected as oracle tokens into the S2S model.
Training uses simulated oracle augmentation, as more of the user utterance becomes available, oracle hints move from vague to ground-truth-like. Random timing jitter teaches the front end to handle delayed hints.
Voice agents do not have to choose between instant but dumb direct S2S and slow but smarter cascades.
Results
KAME moves Moshi-like speech-to-speech from toy answer quality toward cascade quality while keeping near-zero response latency.
The cascade still wins on answer quality, but pays about two seconds of latency. KAME keeps the interruption-friendly feel of direct S2S.
The backend oracle alone is almost as good as the cascade, so the bottleneck is not the LLM. The hard part is timing: start too early and the spoken answer commits before enough information has arrived.
This is probably the right shape for voice agents. Start fast, use the text LLM as it arrives, and learn when to wait.
🧑💻 Open Source
LocalVQE 1.3M parameter GGML/PyTorch model for real-time acoustic echo cancellation, noise removal, and dereverberation at 16 kHz, running causal streaming with 16 ms latency and about 9.6x realtime on Zen4 CPU.
Recursive Language Models MIT-licensed inference library that lets LMs inspect giant prompts through a sandbox/REPL and recursively call themselves over subproblems.
Warp Warp’s terminal/agentic development environment is now open source, mostly Rust, with AGPL/MIT split licensing and support for built-in or external coding agents.
vibevoice.cpp / LocalAI VibeVoice backend LocalAI PR adding a C++/ggml VibeVoice backend for local voice workflows across CPU/GPU backends.
That is it for this issue. Hope you enjoyed it!