
Model check - Higgs Audio V2: Unified Audio Language Modeling at Scale
Going over the new audio language model Higgs Audio V2 and its unified architectural approach

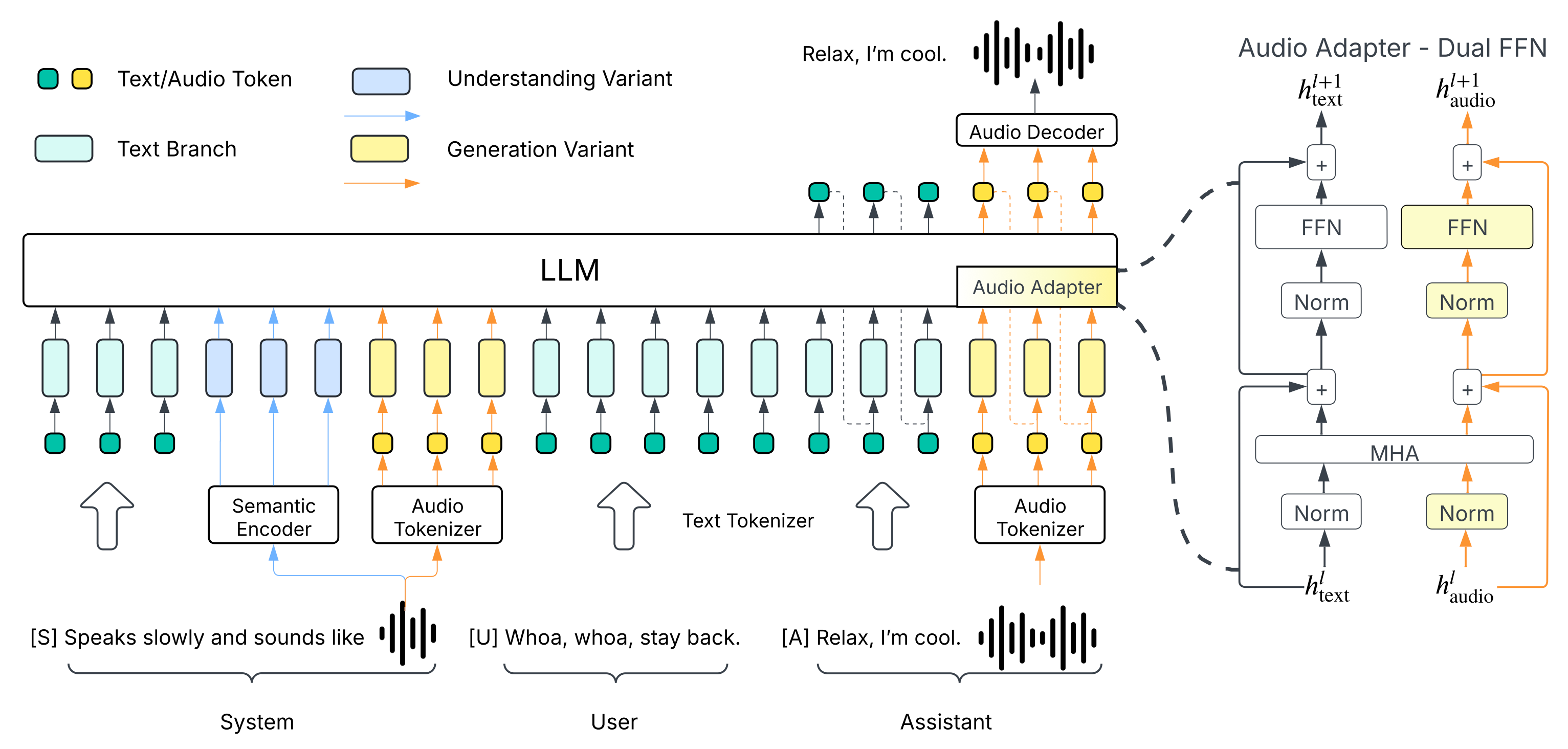
Speech synthesis has evolved rapidly, but most systems still struggle with natural expressiveness and multi-modal understanding. Higgs Audio V2 addresses these limitations through a unified architecture that treats audio as a language, enabling emergent capabilities like multi-speaker dialogues and prosody adaptation without explicit training.
The Challenge
Traditional text-to-speech systems pipeline acoustic modeling and vocoding separately. Neural approaches improved quality but remained constrained by fixed architectures and limited expressiveness. Recent large language models showed promise for audio generation, but faced two critical issues:
Representation bottleneck - Existing audio tokenizers fail to capture both semantic content and acoustic nuance efficiently
Architectural mismatch - LLMs optimized for text struggle with the dense, multi-dimensional nature of audio tokens
Higgs Audio V2 tackles both challenges through smart design choices.
Architecture Overview
The model builds on Llama-3.2-3B with three key innovations:
1. Efficient Audio Tokenization
The tokenizer design focuses on efficiency over conventional methods:
Low frame rate: At 25 fps, the tokenizer compresses 2x better than standard rates while keeping quality. This comes from heavy downsampling (320x with ratios [8,5,4,2]) plus semantic-acoustic feature mixing.
Unified training: Unlike specialized tokenizers, this one handles speech, music, and environmental sounds in a single 24kHz system. Training combines reconstruction loss with semantic knowledge from HuBERT.
Smart quantization: The 12-codebook RVQ gives 2^120 possible combinations while running at just 2 kbps through residual decomposition.
2. DualFFN Architecture
DualFFN is different from typical multimodal models that add separate towers or adapters. Instead of making the model wider, it modifies specific layers:
Parallel processing: Text and audio tokens share attention layers but use different feed-forward networks. The model routes tokens based on their ID ranges (text: 0-128000, audio: 128000+).
Efficiency: By replacing instead of stacking FFN layers, training stays at 91% of the original speed. Only some layers get the dual-path upgrade.
Mixed training: The model keeps text weights frozen while training new audio weights. This preserves text performance while adding audio capabilities.
3. Streaming Generation
The delay pattern solves a key problem: how to generate multiple codebook tokens at once while keeping the model causal.
Time offsets: Instead of generating all 12 codebooks at the same time, codebook k generates tokens for timestep t-k. This keeps causality while allowing parallel generation.
Real-time streaming: The offset structure lets applications start playing audio before the full sequence is done, which is important for low-latency use cases.
4. Special Tokens
Higgs Audio V2 introduces a rich vocabulary of special tokens for fine-grained audio control:
Environmental Context:
<|scene_desc_start|>Audio is recorded from a quiet room.<|scene_desc_end|>
Sound Effects and Audio Events:
<SE>[Laughter]</SE>,<SE>[Music]</SE>,<SE>[Applause]</SE><SE>[Humming]</SE>for melodic humming generationStart/end markers:
<SE_s>[Music]</SE_s>and<SE_e>[Music]</SE_e>
Multi-speaker Support:
Automatic speaker assignment based on dialogue context
Voice profile system with YAML-based speaker descriptions
This token system enables contextual audio generation where the model adapts prosody, background audio, and speaker characteristics based on semantic cues.
Technical Deep Dive
Audio Tokenization Process
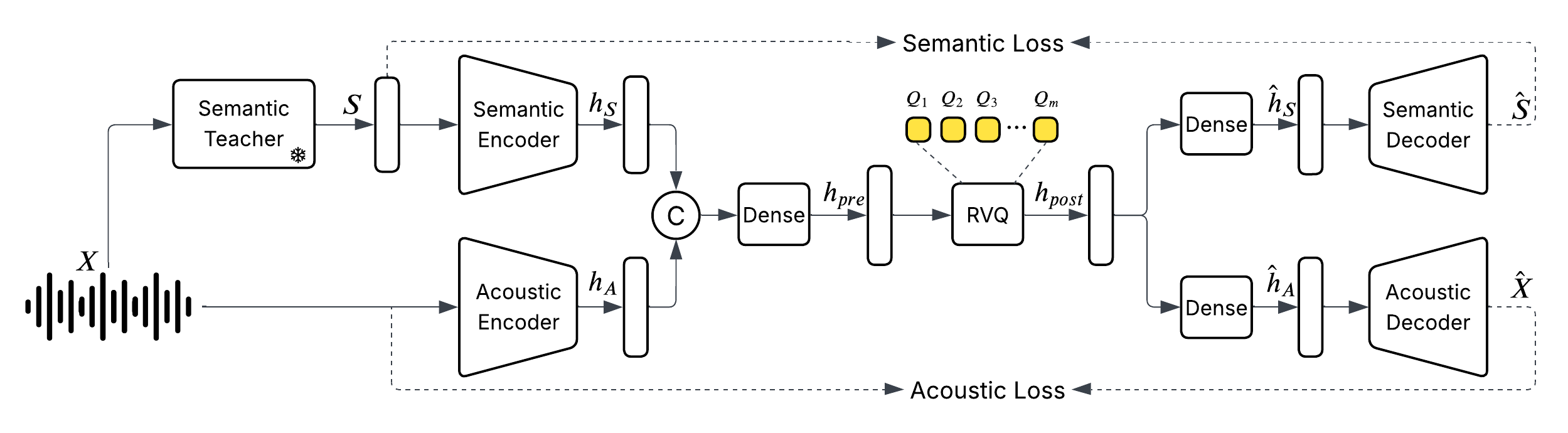
The tokenizer follows this pipeline:
Audio preprocessing - 24 kHz input → mel spectrograms
Encoder - CNNs with ratios [8,5,4,2] → 320x downsampling
Quantization - RVQ with 12 codebooks → discrete tokens
Decoder - Transpose convolutions → reconstructed audio
Mathematical formulation:
Given audio signal x sampled at fs = 24000 Hz
Frame rate: fr = fs / M = 24000 / 960 = 25 fps
Bitrate: fr × Nq × log2(Ncb) = 25 × 12 × 10 = 2000 bps
Where M is hop size (960), Nq is codebooks (12), Ncb is codebook size (1024).
DualFFN Implementation Details
The DualFFN layer replaces standard FFN in selected transformer layers:
class DualFFN(nn.Module):
def __init__(self, text_ffn, audio_ffn_size):
self.text_ffn = text_ffn # Frozen original FFN
self.audio_ffn = LlamaMLP(audio_ffn_size) # New audio FFN
def forward(self, hidden_states, audio_mask):
# Route tokens based on type
text_output = self.text_ffn(hidden_states)
audio_output = self.audio_ffn(hidden_states)
return torch.where(audio_mask, audio_output, text_output)
Training Methodology
Data: AudioVerse dataset with 10M hours of automatically annotated audio processed through a multi-stage pipeline:
ASR models for transcription
Sound event classification for semantic tags
Audio understanding model for quality filtering
Audio Filtering with Audio Understanding Model
A variant of the semantic encoder of the core model is trained and used for audio quality filtering. It has the following model arch.
(32-layer Whisper encoder):
1280 hidden dimensions across 32 transformer layers
20 attention heads per layer, processing 128 mel bins
Identical convolutional preprocessing and positional encoding
Differences
Audio Understanding Model filters audio samples in the training dataset and it uses bidirectional attention.
Semantic encoder: extracts meaning of the input audio for producing text or audio outputs.
Training: Raw Audio → Understanding Model → Quality Score → AudioVerse Dataset
Inference: Reference Audio → Semantic Encoder → Semantic Audio Embeddings → Relevant Output Generation
Training stages:
Tokenizer pretraining - Reconstruction loss on diverse audio
LLM adaptation - Frozen text weights, trainable audio components
Joint fine-tuning - End-to-end optimization with delay pattern
Partial freezing strategy: Original text embeddings and output projections remain frozen up to vocabulary index 128000, with new audio tokens (128000+) fully trainable. This preserves text capabilities while enabling audio generation.
Evaluation Framework and Results
Evaluation Results
The evaluation covers both standard TTS metrics and new capabilities:
Standard TTS Metrics:
SeedTTS-Eval: 2.44% WER with 67.70% speaker similarity - good intelligibility with better voice copying
Multi-speaker tasks: 18.88% WER on dialogue with 51.95% speaker consistency
New Capabilities:
EmergentTTS-Eval: 75.7% preference over GPT-4o-mini-tts on emotions, 55.7% on questions
Shows the model can generate appropriate prosody without explicit emotional training
They released EmergentTTS codebase public. It’s a great addition to any speech generation eval stack.
DualFFN Validation
Testing DualFFN on LLaMA-3.1-1B shows:
Better performance: 15% WER improvement (English) and 12% (Chinese) with 6-8% speaker similarity gains
Low overhead: <10% training time increase
The improvements work across languages, suggesting DualFFN learns general audio-text patterns rather than language-specific tricks.
Emergent Capabilities
Beyond traditional TTS metrics, Higgs Audio V2 demonstrates several emergent behaviors:
1. Zero-Shot Voice Cloning
The model performs voice cloning through audio understanding and cross-modal attention:
Technical Implementation:
Reference audio encoding via bidirectional Whisper encoder
Audio-text cross-attention in LLM layers for voice characteristic transfer
Speaker embedding extraction from 3-10 second reference clips
Multi-speaker consistency maintained through speaker tokens
# Voice cloning example
messages = [
Message(role="system", content=system_prompt),
Message(role="user", content=[
AudioContent(audio=reference_audio_path), # Reference voice
"Generate this text in the reference voice: Hello world"
])
]
2. Automatic Voice Assignment
Given multi-speaker dialogue without voice specifications, the model assigns appropriate, consistent voices based on context and content.
3. Prosody Adaptation
During narrative passages, the model automatically adjusts rhythm, pace, and emphasis based on content semantics.
4. Cross-modal Generation
Simultaneous speech and background music generation, with appropriate volume and harmonic compatibility. The model uses contextual cues from scene descriptions to generate appropriate background audio:
# Example: Automatic background music generation
system_prompt = (
"Generate audio following instruction.\n\n"
"<|scene_desc_start|>\n"
"Audio is recorded in a cozy café with soft jazz playing.\n"
"<|scene_desc_end|>"
)
# Model automatically generates speech with café ambiance
5. Multilingual Consistency
Voice characteristics maintained across language switches within the same speaker.
These capabilities emerge from the unified training on diverse audio-text pairs.
Implementation Considerations
Memory and Compute
Model size: 3.6B LLM + 2.2B audio adapter = 5.8B total parameters
Memory: ~24GB GPU memory for inference
Speed: Real-time on RTX 4090, 2-3x real-time on A100
Performance Optimizations
CUDA Graph Acceleration:
Static KV cache with pre-allocated sizes (1K, 4K, 8K tokens)
Graph capture after 2 warmup iterations
Memory pooling for efficient GPU memory management
Significant speedup for production serving scenarios
Repetition-Aware Sampling (RAS):
Prevents audio repetition artifacts during generation
Configurable window length and maximum repeat counts
Essential for long-form audio generation quality
Integration Patterns
Three usage modes:
Direct API - Python interface for batch processing
Streaming server - HTTP/WebSocket for real-time applications
vLLM integration - High-throughput serving with OpenAI-compatible API
vLLM Production Serving:
OpenAI chat completions API compatibility
Batched inference for high-throughput scenarios
Streaming support for real-time audio generation
Base64 audio encoding for web service integration
# Launch vLLM server
python -m vllm.entrypoints.openai.api_server \
--model bosonai/higgs-audio-v2-generation-3B-base \
--dtype bfloat16 \
--api-key your-api-key
# Basic usage
serve_engine = HiggsAudioServeEngine(
model_path="bosonai/higgs-audio-v2-generation-3B-base",
tokenizer_path="bosonai/higgs-audio-v2-tokenizer"
)
output = serve_engine.generate(
chat_ml_sample=ChatMLSample(messages=messages),
max_new_tokens=1024,
temperature=0.3
)
Limitations
Latency: 2-3 second end-to-end delay limits real-time interaction
Context length: 8K token limit constrains long-form content
Controllability: Limited fine-grained prosody control mechanisms
Code and models available at: https://github.com/boson-ai/higgs-audio