
Model Check - MiMo-Audio: Scaling Speech Pre-Training to 100M Hours
Going over the code and the technical report of the new Speech LM model from Xiaomi that rivals GPT4o-audio and Gemini

MiMo-Audio is Xiaomi's 7B parameter model that processes speech and text through a unified architecture. Trained on 100+ million hours of audio data—10x larger than existing open-source models— that results in emergent capabilities like voice conversion, speech translation, and cross-modal reasoning through few-shot learning, demonstrating speech scaling laws similar to text language models.
TL;DR:
Scale Unlocks Emergent Abilities: 100M+ hours (10x larger than existing models) creates phase transition at ~0.7T tokens with genuine few-shot abilities
Unified Architecture: Patch-based audio representation (25Hz→6.25Hz) bridges text-speech mismatch; two-stage training preserves text capabilities while adding audio generation
SOTA Open-Source Performance: Best modality consistency on SpeechMMLU benchmark; strong across audio understanding benchmarks.
Emergent Abilities at Scale
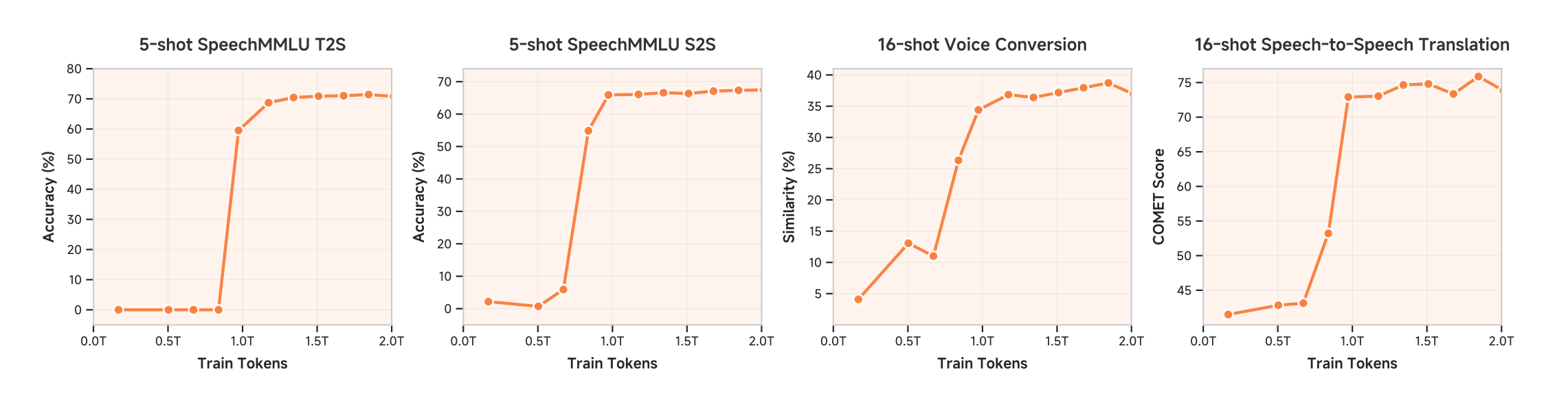
Evidence for "Phase Transition":
Performance jumps after ~0.7 trillion tokens across multiple benchmarks
5-shot SpeechMMLU (T2S, S2S), 16-shot voice conversion, S2S translation
Emergent Capabilities (not explicitly trained):
Few-shot voice conversion
Emotion and speaking rate modification
Speech denoising
Speech-to-speech translation
Core Contribution: Proving that text scaling paradigms work also for speech.
Architecture Deep Dive
MiMo-Audio-Tokenizer (1.2B Parameters)
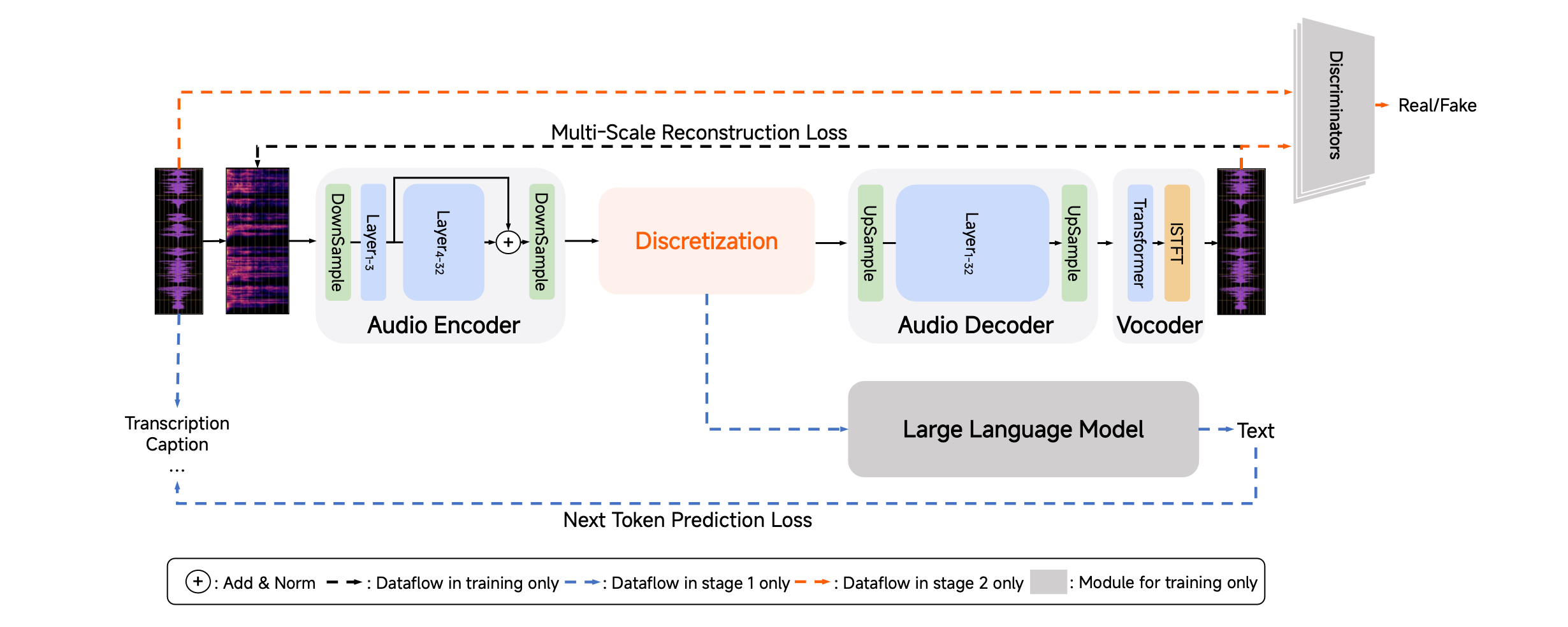
Core Specs:
8-layer Residual Vector Quantization (RVQ)
25Hz token rate → 25*8 = 200 tokens/second
Preserves both semantic + acoustic information
K-means based vocabulary initialization.
Two-Stage Training:
Stage 1: 11M+ hours, joint audio reconstruction + A2T objectives
Loss weights: λ_A2T = 10.0, λ_recon = 1.0, λ_commit = 1.0
Stage 2: Adversarial fine-tuning with Multi-Period + Multi-Scale STFT discriminators
Frozen encoder/discretization, train decoder/vocoder
Approach: From-scratch training at massive scale vs. building on existing semantic models
Solving Semantic vs Acoustic Tokens Conflict
The Core Trade-off:
Semantic tokens: Capture linguistic content, lose acoustic details (speaker identity, prosody)
Acoustic tokens: Preserve audio quality, struggle with language understanding
Traditional solution: Choose one path—semantic for ASR, acoustic for voice cloning
MiMo-Audio's Approach:
Add layer-3 hidden states to final-layer output via element-wise summation
Theory: Early layers (L3) = acoustics, final layers (L32) = semantics
Implementation: Element-wise summation combines both representations
❓No ablation in the paper. Improvements might just the output of the larger scale training. ❓
Audio Language Model
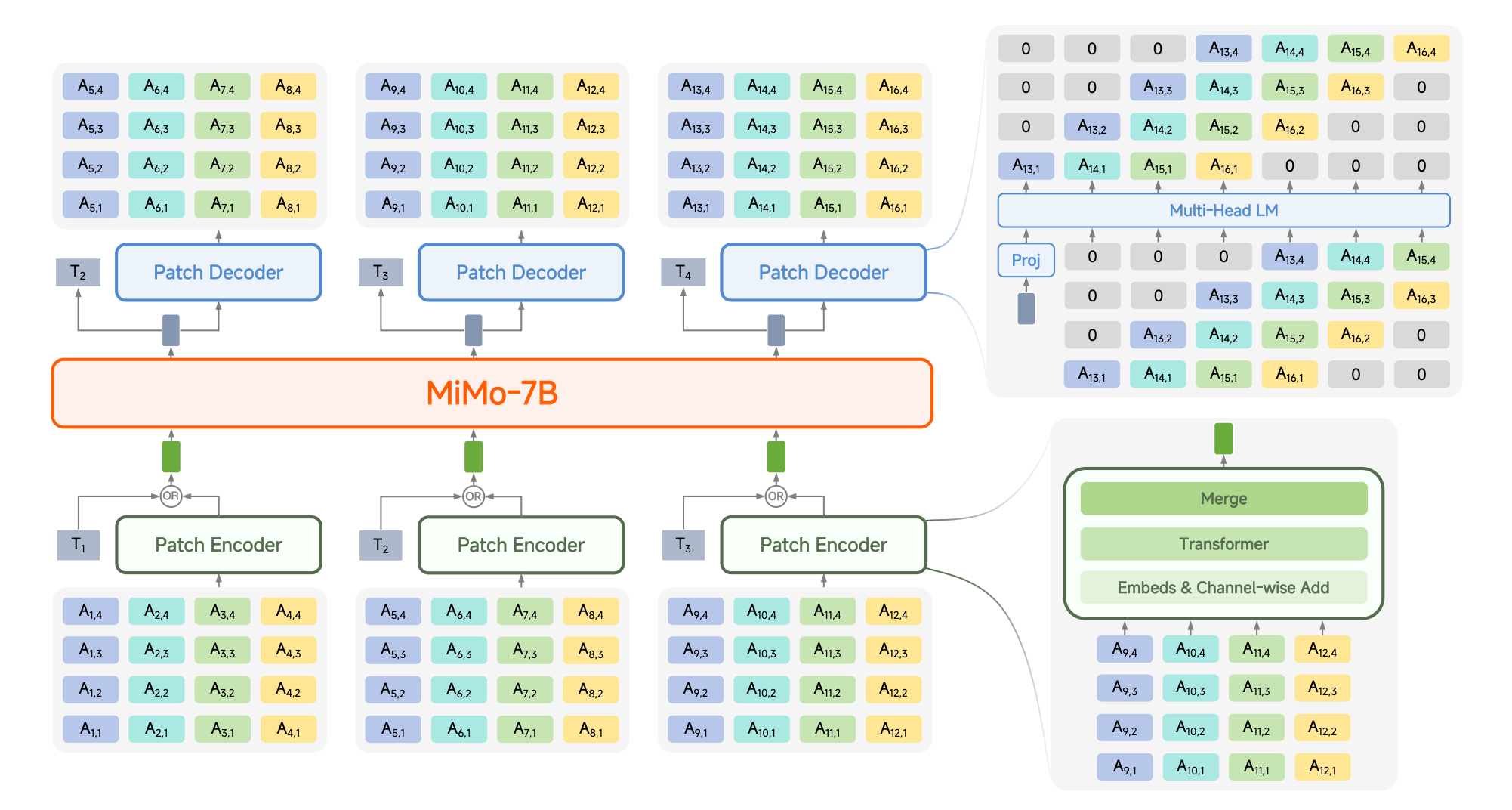
The Challenge: Audio 200 tokens/sec vs text ~4 words/sec sequence length
Solution: Patching audio tokens (25Hz → 6.25Hz) before LLM
Three-Component Architecture:
Patch Encoder (6 Layers): Groups 4 consecutive RVQ tokens, bidirectional attention
LLM Backbone: MiMo-7B-Base with unified next-token/patch prediction
Patch Decoder (16 Layers): Generates 25Hz RVQ sequence with delayed pattern output.
Layer-specific delays: 0-1-2-3-4-5-6-7 prevent simultaneous RVQ prediction
Result: Efficient cross-modal transfer while maintaining fine-grained audio generation.
Implementation Insights
Training Strategy
Two-Stage Progressive Approach:
# Stage 1: Understanding Only
loss_weights = [1, 0, 0, 0, 0, 0, 0, 0, 0] # Text only
learning_rates = {'patch_encoder': 2e-4, 'llm': 3e-5}
# Stage 2: Understanding + Generation
loss_weights = [100, 12, 8, 6, 4, 2, 2, 1, 1] # Text + RVQ layers
learning_rates = {'patch_encoder': 2e-4, 'llm': 3e-5, 'patch_decoder': 2e-4}
Key Architecture Specs:
Patch Encoder: 1024 dim, 64 heads, 6 layers
LLM Backbone: 4096 dim, 32 heads, 36 layers
Patch Decoder: 1024 dim, 64 heads, 16 layers
Context: 8192 tokens, 4-patch audio chunks
Delay Pattern: [0,1,2,3,4,5,6,7] for 8 RVQ layers
Shared embedding tables between encoder/decoder for efficiency
Training at Unprecedented Scale
Scale Specifications
Data: 100+ million hours (10x larger than existing open-source)
Pipeline: Automated processing, multi-dimensional annotation, quality control
Sources: Podcasts, audiobooks, news, interviews, conference recordings
Content: Daily communication, entertainment, business, arts, research
Two-Stage Progressive Training
Stage 1 - Understanding (2.6T tokens):
1.2T text + 1.4T audio tokens (6.25Hz)
Tasks: Speech-text interleaved, ASR, audio captioning, text pre-training
Loss computed only on text tokens (preserves text capabilities)
Stage 2 - Understanding + Generation (5T tokens):
2.6T text + 2.4T audio tokens
Adds: Speech continuation, TTS, instruction-following TTS
All parameters trained with weighted losses
They use an internal TTS model to generate training data for spoken dialogue
Performance Analysis
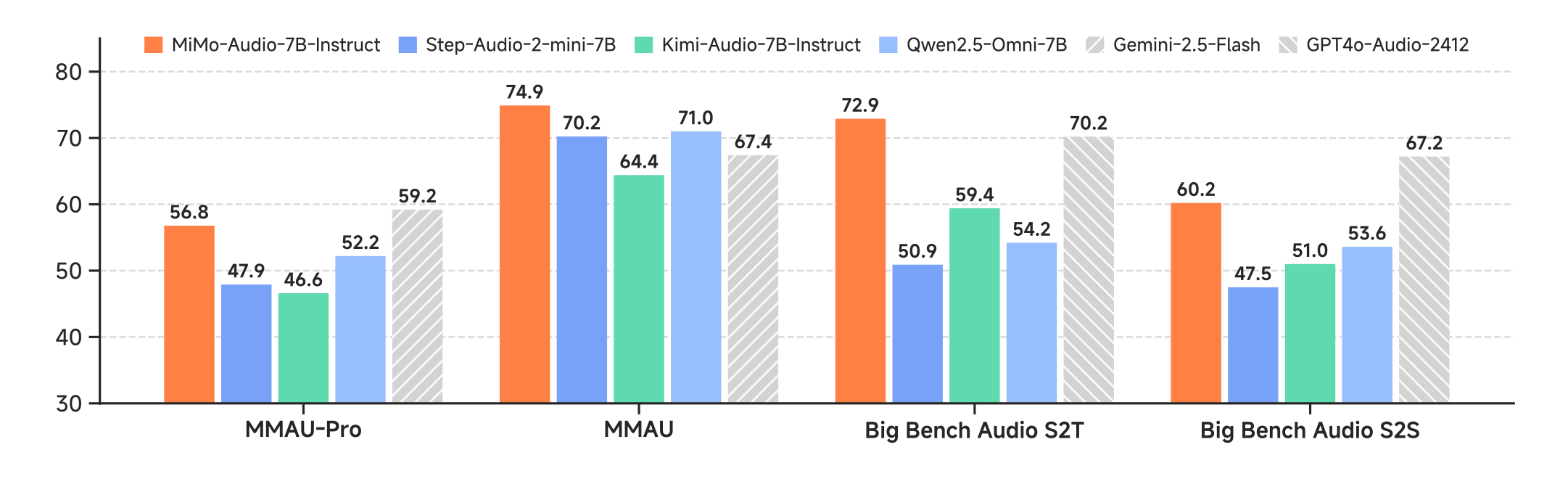
Speech Intelligence (SpeechMMLU)
MiMo-Audio S2S: 69.1% (best evaluated)
Step-Audio2-mini S2S: 51.8%
MiMo-Audio Modality Gap: 3.4 points (T2T: 72.5%, S2S: 69.1%)
Competitors: 22.3+ point gaps
Key Finding: Consistent reasoning across text/speech modalities
Audio Understanding (MMAU)
MiMo-Audio: 66.0% overall
Step-Audio2-mini: 60.3%
Balance: Speech 67.6%, sound 65.2%, music 65.3%
Few-Shot Learning Evidence
Voice Conversion: 16-shot in-context learning without parameter updates
S2S Translation: Cross-lingual generation maintaining speaker characteristics
Style Transfer: Emotion/rate conversion across prosodic dimensions
Limitation: Heavy reliance on automatic metrics; perceptual quality gaps unclear
Thanks for reading… 👋
Resources
Model Weights: MiMo-Audio Collection on HuggingFace
Source Code: MiMo-Audio GitHub Repository
Technical Report: MiMo-Audio Technical Report
Evaluation Suite: MiMo-Audio-Eval
Demo Interface: Interactive MiMo-Audio Demos