


Paper check: Merging LLMs at Pre-training, Considering Token Probabilities at RL
🔬Two papers in scope: "Model Merging in Pre-training for LLMs" and "Do Not Let Low-Probability Tokens Over-Dominate in RL"

Here are two papers that target:
Paper1: improving pre-training performance of an LLM by merging model checkpoints along the training trajectory and
Paper2: improving post-training RL efficiency by avoiding the low-probability token dominance.
Model Merging in Pre-training of Large Language Models

What's new
Pre-trained Model Average (PMA) strategy for model merging during pre-training of large language models (LLMs).
Focus on merging checkpoints from stable training phases to enhance performance and reduce training costs.
How it works
PMA merges weights from multiple checkpoints along the training trajectory.
Three merging methods evaluated: Simple Moving Average (SMA), Exponential Moving Average (EMA), and Weighted Moving Average (WMA).
Merging involves assigning weights to models based on their training recency, with SMA treating all models equally, EMA giving more weight to recent models, and WMA using linearly increasing weights.
The optimal merging interval and number of models to merge are determined based on model size, with findings suggesting specific intervals (e.g., 8B tokens for 1.3B models).
PMA-init technique applied during continual training (CT) and supervised fine-tuning (SFT) stages to stabilize training and improve performance.
Results
Significant performance improvements observed across various downstream tasks after applying PMA.
Merged models showed better stability during training, reducing loss spikes and improving GradNorm metrics.
PMA-init led to smoother training dynamics and better initialization weights, enhancing downstream performance.
Why it matters
Provides a practical framework for enhancing the efficiency of LLM pre-training.
Leads to a more stable post-training and improved performance
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
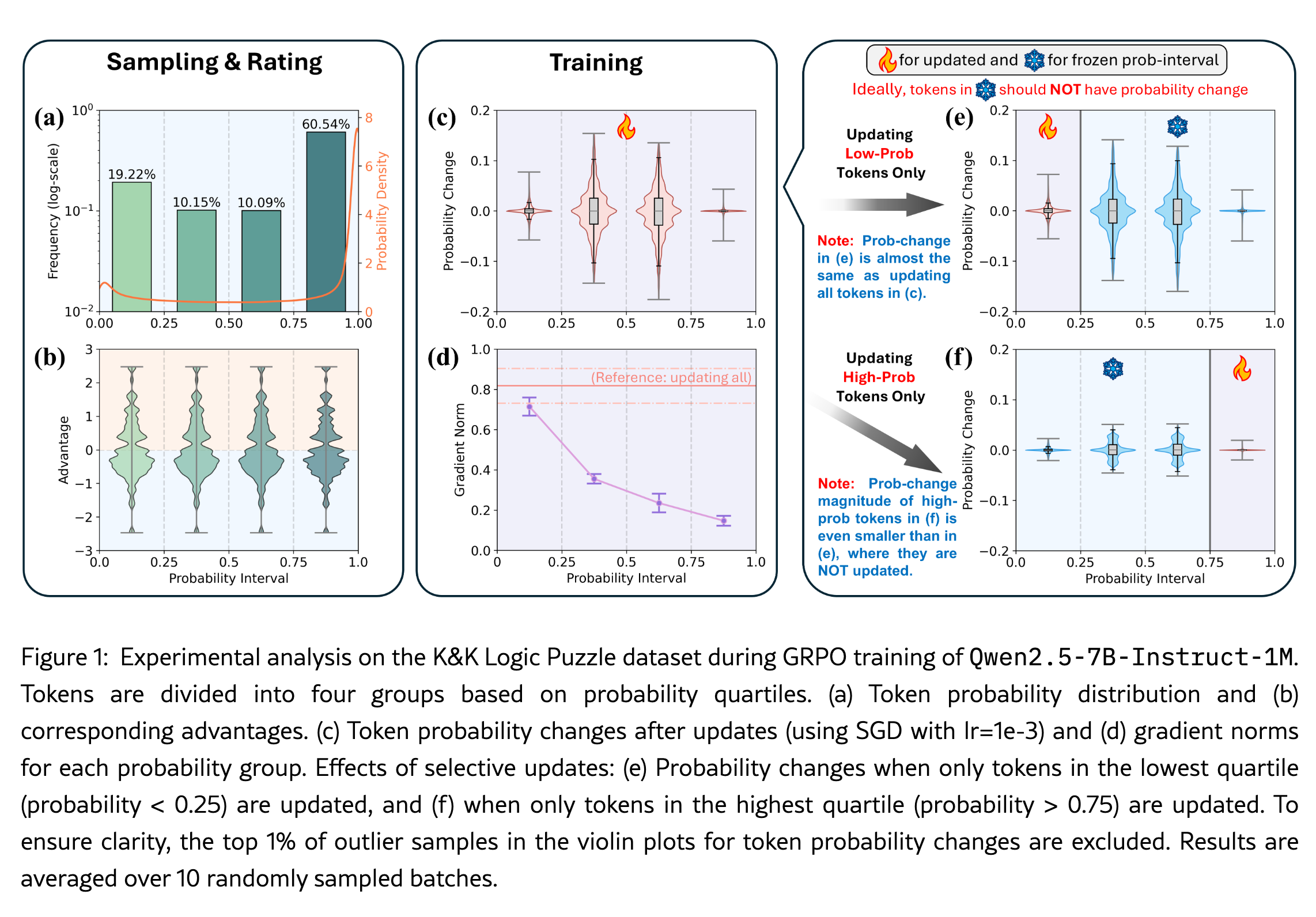
What's new
Low-probability tokens' dominates RL (GRPO) training for LLMs.
“Dominates” means, low-prob tokens pull the model too much in the wrong direction by relatively big gradient updates.
Two methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti) to mitigate this issue.
How it works
Advantage Reweighting:
Adjusts the weight of tokens based on their probabilities.
Tokens with lower probabilities receive linearly smaller update weights.
This reduces errors in update directions for high-probability tokens.
Low-Probability Token Isolation (Lopti):
Divides tokens into low-probability and high-probability groups based on a predefined threshold.
Updates low-probability tokens first, followed by high-probability tokens.
This order of updates allows for better influence on high-probability tokens, ensuring they are adjusted correctly based on the previous updates.
Results
On K&K Logic Puzzle dataset:
GRPO enhanced with Advantage Reweighting improved performance by 35.9%.
GRPO with Lopti improved performance by 38.5%.
Combined use of both methods resulted in a 46.2% performance increase.
On math-related datasets, improvements were also observed, demonstrating the methods' effectiveness across various tasks.
Why it matters
Enhances the efficiency and effectiveness of updates in RL training, leading to better model performance.